原文地址:Let’s Build A Simple Interpreter. Part 14.
Only dead fish go with the flow.
如我在上篇文章中承诺的,今天我们终于要深入研究作用域这个主题了。
Figure 1: img01
下面是我们今天要学习的内容:
- 我们会学习作用域,它们为什么有用,以及在代码中怎样用符号表来实现它们
- 我们会学习嵌套作用域以及链式限定作用域的符号表怎样被用来实现嵌套作用域。
- 我们会学习怎样解析带有形式参数过程的声明,以及怎样在代码中表示一个过程符号。
- 我们会学习怎样扩展我们的语义分析器使之在嵌套作用域存在的情况下语义检查。
- 我们会学习更多关于名字解析的内容和语义分析器怎样在嵌套作用域存在的情况下把名字 解析为它们的声明。
- 我们会学习怎样构建一个作用域树。
- 我们今天还会学习怎样写我们自己的 源码到源码编译器 (source-to-source compiler)!稍后在本文中我们会看到这和作用域的关系。
让我们开始吧!或者我应该说,让我们钻研吧!
Table of Contents
作用域及作用域内的符号表
什么是作用域? 作用域 是程序中一个名字可以被使用的词法区域(textual region)。 让我们看一下下面的示例程序:
1 | program Main; var x, y: integer; begin x := x + y; end. |
在 Pascal 中, PROGRAM 关键字(顺便提一下,不区分大小写)引入了一个新的作用
域,通常称为全局作用域(global scope),所以上面的程序有一个全局作用域且被声明的
变量 x 和 y 都是在整个程序内都可见和可使用的。在上面的情况下,词法区域由关
键字 program 开始,到关键字 end 后跟一个点结束。在那个词法区域中名字 x
和 y 都可以被使用,所以这些变量(变量声明)的作用域就是整个程序:
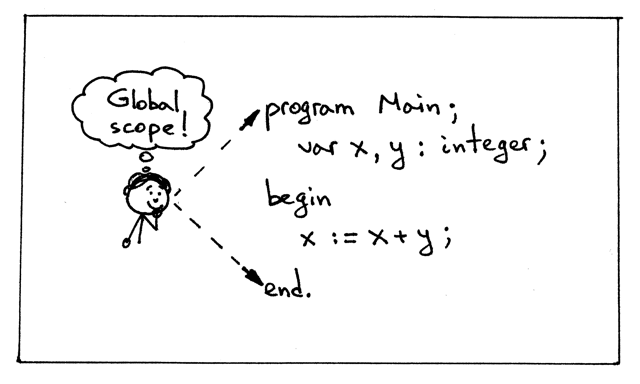
Figure 2: img02
当看到上面的源码,尤其是表达式 x := x + y 时,你直觉上知道它可以编译(或解释)
通过而不会有问题,因为这个表达式中变量 x 和 y 的作用域是全局作用域,且表达
式 x := x + y 中对变量 x 和 y 的引用会被解析为声明过的整型变量 x 和
y. 如果你用过任何一门主流的编程语言,就不应该觉得不对劲。
当我们讨论一个变量的作用域时,我们其实是在讨论它声明的作用域:
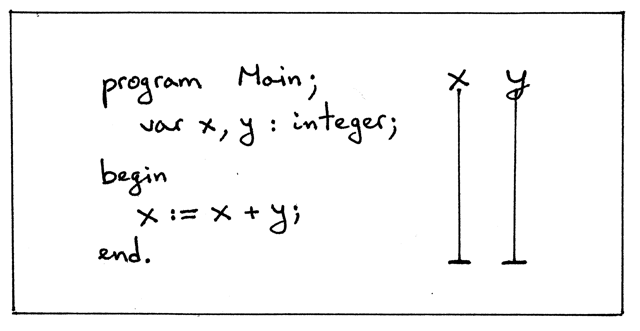
Figure 3: img03
在上面的图片中,竖直的线表示被声明变量的作用域、被声明过的名字 x 和 y 可以 使用的词法区域,即在这个文本区域内它们是可见的。如你所见, x 和 y 的作用域 是整个程序,这也是竖线所表示的。
Pascal 程序所用的被称为词法作用域(lexically scoped,或静态作用域 statically
scoped),因为你可以只看源码而不用执行这个程序,单纯根据文本规则就可以确定哪个
名字(引用)会解析到哪个声明。例如在 Pascal 中,像 program end 这样的词法
关键字就划定了一个作用域的文本边界:
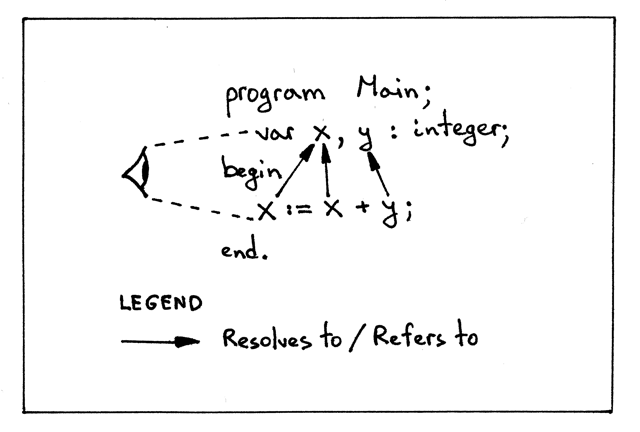
Figure 4: img04
为什么作用域会有用呢?
- 每个作用域创建了一个隔离的名字空间,这意味着在一个作用域内声明的变量不能从它 外面访问它。
- 你可以在不同的作用域中重用相同的名字,且只需看到源码,就可以确切地知道在程序 中的每个地方某个名字引用哪个声明。
- 在嵌套作用域中,你可以重新声明一个与外层作用域相同名字的变量,从而在事实上隐 藏了外层的声明,这就给了你对访问外层作用域不同变量的控制能力。
除了全局作用域,Pascal 还支持嵌套作用域,每个过程声明都会引入新的作用域,这就 意味着 Pascal 支持嵌套作用域。
当我们讨论嵌套作用域时,使用作用域级别来表示它们的嵌套关系会很方便。通过名字来 指代作用域也会很方便。当开始讨论嵌套作用域时,我们会同时使用作用域级别和作用域 名字。
让我们看一下下面的示例程序,并对程序中的每个名字都写上下标来弄清楚:
- 每个变量(符号)都是在哪一级别被声明的
- 一个变量名引用了哪一级别的哪个声明:
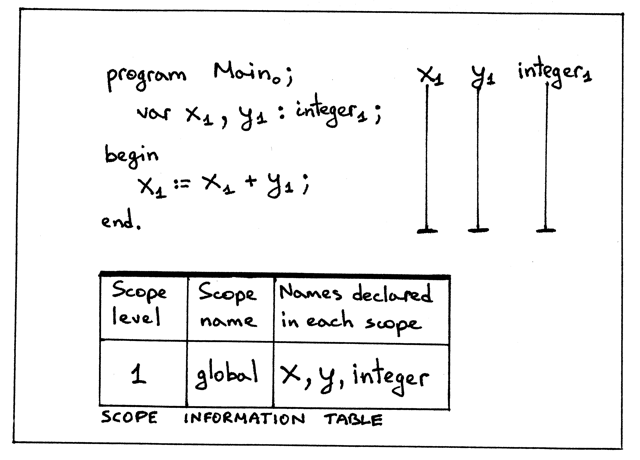
Figure 5: img05
从上面的图片中我们可以看出几点:
- 我们只有一个作用域,即全局作用域,由关键字 PROGRAM 引入
- 全局作用域是级别 1
- 变量(符号) x 和 y 在声明在级别1(全局作用域)上
- 整型内置类型也是在级别1上声明的
- 程序名 Main 有一个下标0. 你可能会奇怪为什么程序名在级别0?这是要表示清楚程 序名并不在全局作用域中而是在另一个外层作用域里,即级别0.
- 变量 x 和 y 的作用域是整个程序,由竖线可以看出来
- 作用域信息表展示了程序中的每一级别所对应的作用域级别、作用域名字和在该作用域 中声明的名字。这个表的目的是总结并在视觉上展示一个程序中作用域的不同信息。
我们怎样在代码中实现作用域的概念呢?为了在代码中表示作用域,我们需要一个符号作 用域表(scoped symbol table)。我们已经知道了符号表,那符号作用域表又是什么呢? 符号作用域表 基本上就是一个符号表加上一些修改,你很快就会看到的。
从现在起,我们会用作用域这个词同时指代作用域这个概念和符号作用域表(即代码中作 用域的实现)。
尽管在代码中作用域是由 ScopedSymbolTable 类的一个实例表示的,我们为方便起见
还是在代码中用名为 scope 的变量。所以当你在我们解释器的代码中看到名为
scope 的变量时,就要知道它实际上指向的是一个符号作用域表。
好了,让我们增强我们的 SymbolTable 类,将其重命名为类 ScopedSymbolTable,
添加两个新的字段 scope_level 和 scope_name, 并修改符号作用域表的构造函数。
与此同时,让我们修改 __str__ 方法来打印更多信息,即 scope_level 和
scope_name. 下面是新版本的符号表,即 ScopedSymbolTable:
1 | class ScopedSymbolTable(): |
让我们同样修改语义分析器的代码来使用变量作用域而不是 symtab, 并从方法
visit_VarDecl 中移除检查源码中重复标识符的语义检查以减少程序输出中的干扰。
下面是一段展示语义分析器如何实例化 ScopedSymbolTable 类的代码:
1 | class SemanticAnalyzer(NodeVisitor): |
你可以在文件 scope01.py 中找到所有的改变。下载这个文件,在命令行上运行它并检查 它的输出。下面是我得到的结果:
$ python scope01.py
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: x
Lookup: INTEGER
Insert: y
Lookup: x
Lookup: y
Lookup: x
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
你应该看大部分的输出都很熟悉。
现在你知道了作用域的概念和怎样通过使用符号作用域表在代码中实现作用域,是时候 讨论嵌套作用域以及对符号作用域表做些有意思的修改,而不只是添加两个简单的字段了。
带有形式参数的过程声明
让我们看一个文件 nestedscopes02.pas 中的示例程序,它包含一个过程声明:
1 | program Main; var x, y: real; procedure Alpha(a : integer); var y : integer; begin x := a + x + y; end; begin { Main } end. { Main } |
我们注意到的第一件事就是我们有一个带参数的过程,而我们尚未学习如何处理它。让我 们在继续作用域的讨论之前,花点时间来学习如何处理形式的过程参数以填补上这个空白。
ASIDE: 形式参数(formal parameters)是在过程声明时出现的参数。实参(Arguments,也 称为实际参数,actual parameters)是在某个特定的过程调用时传给一个过程的不同的变 量和表达式。
下面是我们为了支持带参数的过程声明所要做的修改:
增加
ParamAST 结点1
2
3
4class Param(AST):
def __init__(self, var_node, type_node):
self.var_node = var_node
self.type_node = type_node修改
ProcedureDecl结点的构建函数以接受一个额外的参数:params1
2
3
4
5class ProcedureDecl(AST):
def __init__(self, proc_name, params, block_node):
self.proc_name = proc_name
self.params = params # a list of Param nodes
self.block_name = block_name修改
declarations规则以反映过程声明子规则的变化1
2
3
4
5def declarations(self):
"""declarations : (VAR (variable_declaration SEMI)+)*
| (PROCEDURE ID (LPAREN formal-parameter_list RPAREN)? SEMI block SEMI)*
| empty
"""增加
formal_parameter_list规则和方法1
2
3
4def formal_parameter_list(self):
""" formal_parameter_list : formal_parameters
| formal_parameters SEMI formal_parameter_list
"""增加
formal_parameters规则和方法1
2
3def formal_parameters(self):
""" formal_parameters : ID (COMMA ID)* COLON type_spec """
param_nodes = []
增加了上面方面和规则后,我们的 parser 就能够解析像这样的过程声明了(我为了简洁 没有展示所声明过程的主体):
1 | procedure Foo; procedure Foo(a : INTEGER); procedure Foo(a, b : INTEGER); procedure Foo(a, b : INTEGER; c : REAL); |
让我们为示例程序生成 AST。下载 genastdot.py 并在命令行上运行以下命令:
1 | $ python genastdot.py nestedscopes02.pas > ast.dot && dot -Tpng -o ast.png ast.dot |
下面是生成的 AST 的图片:
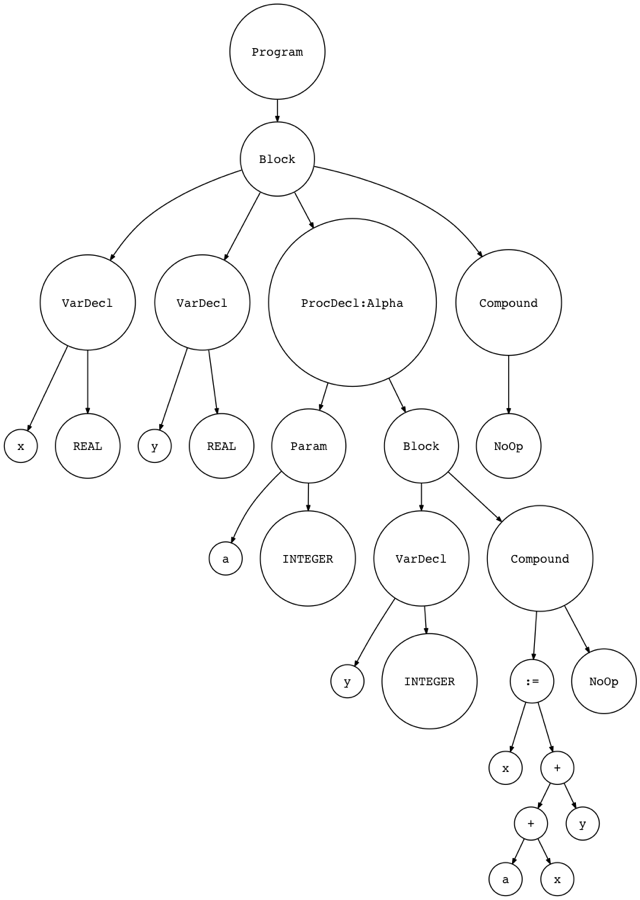
Figure 6: img06
你可以看到图片中的 ProcedureDecl 结点有 Param 结点作为它的子结点。
你可以在文件 spi.py 中找到完整的改动。花些时间研究一下这些改动。你在之前已经做 过类似的修改了;它们应该很好理解且你应该可以自己实现它们。
过程符号
在讨论过程声明的主题时,让我们也聊聊过程符号(procedure symbols)。
和变量声明和内置类型声明一样,对于过程也有一个单独的符号类别。让我们为过程符号 新建一个单独的符号类:
1 | class ProcedureSymbol(Symbol): |
过程符号有一个名字(即过程名),它们的类别是过程(被编码进了类名),类型是
None 因为在 Pascal 中过程不返回任何东西。
过程符号还保存了关于过程声明的附加信息,即如上面的代码所示,它保存了过程的形式 参数。
加上过程符号,我们新的符号层级如下所示:
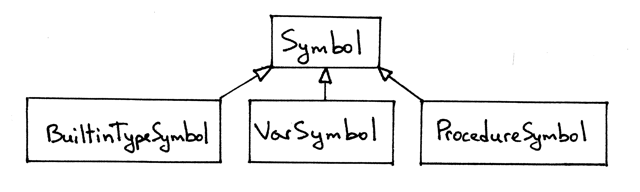
Figure 7: img07
嵌套作用域
说完这个知识点后,让我们回到我们的的程序以及嵌套作用域的讨论:
1 | program Main; var x, y : real; procedure Alpha(a : integer); var y : integer; begin x := a + x + y; end; begin { Main } end. { Main } |
在这里事情变得更有趣了。在声明一个新的过程时,我们就引入了一个新的作用域,而这
个作用域嵌套在了由 PROGRAM 引入的全局作用域,所以这是一个有嵌套作用域的
Pascal 程序的例子。
一个过程的作用域就是这个过程的整个主体。过程作用域的开始是由关键字 PROCEDURE
标识的,而由关键字 END 和一个分号标识结束。
让我们在程序中用下标表示一些额外的信息:
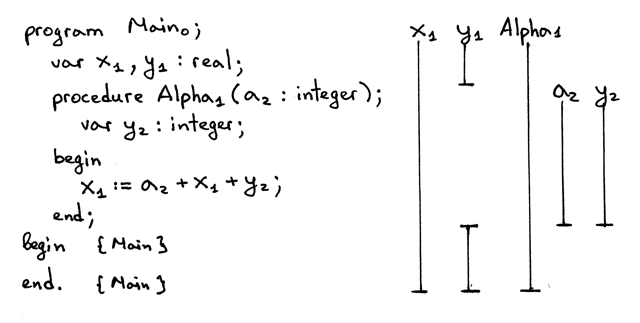
Figure 8: img08
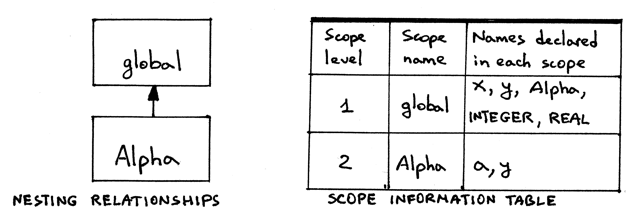
Figure 9: img09
从上面的图片中我们可以看出几点:
- 这个 Pascal 程序有两个作用域级别:级别1 和级别2
- 嵌套关系图展示了作用域
Alpha是嵌套在作用域global中的,所以有两个级别:global作用域在级别1,Alpha作用域在级别2 - 过程声明
Alpha的作用域级别比在其中声明的变量小一级。过程声明Alpha的作 用域级别是 1,而它里面的变量 a 和 y 的级别是 2。 - 在
Alpha内部声明的变量 y 隐藏了全局作用域中声明的变量 y. 你可以看到 y1 的竖线上有一段空白(顺便提一下,1是一个下标,不是变量名的一部分,变量名 只是 y),也可以看到变量声明 y2 的作用域是过程Alpha整个过程体。 - 作用域信息表,如你所知,展示了作用域级别,对应级别作用域的名字,以及在其中声 明的变量名。
- 在这张图中,也可以看到我省略了
integer和real类型的作用域,因为它们总 是声明在级别 1 的全局作用域,所以我为了节省可视空间就不会再给它们画下标了, 不过你会一遍又一遍地在全局作用域符号表中看到它们。
下一步就是讨论实现细节了。
首先,让我们把重点放在变量和过程声明上。然后,我们会讨论变量引用以及名字解析在 嵌套作用域存在的情况下如何进行。
为了讨论方便,我们会使用一个修剪过的程序版本。下面的版本没有变量引用:它只有变 量和过程声明:
1 | program Main; var x, y : real; procedure Alpha(a : integer); var y : integer; begin end; begin { Main } end. { Main } |
你已经知道如何在代码中使用作用域符号表来表示一个作用域了。现在我们有两个作用域:
全局作用域和过程 Alpha 引入的作用域。由我们所用的方法可知应该有两个作用域符
号表:全局作用域一个, Alpha 作用域一个。我们如何在代码中实现呢?我们将会扩
展语义分析器来为每一个作用域创建一个单独的作用域符号表,而不仅仅只为全局作用域
创建。作用域的构建和以前一样,会在遍历 AST 的过程中进行。
首先,我们需要决定在语义分析器的哪里创建我们的作用域符号表。回想一下关键字
PROGRAM 和 PROCEDURE 会引入新的作用域。在 AST 中,相应的结点是 Program
和 ProcedureDecl 。因此我们会修改 visit_Program 方法并增加
visit_ProcedureDecl 方法来创建作用域符号表。让我们从 visit_Program 方法开
始:
1 | def visit_Program(self, node): |
这个方法有不少改动:
- 在访问 AST 中的结点的时候,我们首先打印出了我们要进入哪个作用域,在这里是
global. - 我们新建了一个单独的作用域符号表来表示全局作用域。当构建
ScopedSymbolTable的实例时,我们明确地向构建函数传入了作用域的名字和作用域级别这两个参数。 - 我们将新创建的作用域赋值给变量
current_scope. 其他访问者方法在向作用域符 号表插入或查询的时候会用到current_scope. - 我们访问了一个子树(block)。这部分修改前也有。
- 在离开全局作用域时我们打印出了它的(作用域符号表中的)内容
- 我们还打印了离开全局作用域的提示消息
现在让我们添加 visit_ProcedureDecl 方法。下面是它的完整源码:
1 | def visit_ProcedureDecl(self, node): |
让我们过一下这个方法的内容:
- 这个方法做的第一件事是新建了一个过程符号并把它插入到当前作用域中,在示例程 序中就是全局作用域。
- 然后方法打印出了进入这个过程作用域的信息。
- 然后我们为保存过程的参数和变量声明创建了一个新的作用域。
- 我们将过程作用域赋值给变量
self.current_scope以表明这是当前的作用域,而 所有的符号操作(插入和查找)会使用当前作用域。 - 然后我们处理了过程的形式参数,将它们插入到当前作用域并添加到过程符号中。
- 然后我们访问 AST 子树的剩下部分──过程的主体。
- 最后,我们在离开这个结点去访问下一个结点(如果有的话)之前,打印出离开这个 作用域的消息。
现在我们需要做的是修改其他语义分析器访的问者方法以在插入和查找符号时使用
self.current_scope. 让我们动手吧:
1 | def visit_VarDecl(self, node): |
visit_VarDecl 和 visit_Var 方法现在都会使用 current_scope 来插入和/或查
找符号。特别地,对于我们的示例程序来说, current_scope 可能指向 global 作
用域或 Alpha 作用域。
我们还需要修改语义分析器并在构建函数中将 current_scope 设置为 None:
1 | class SemanticAnalyzer(NodeVisitor): |
克隆本文代码的 GitHub 仓库,运行 scope02.py(它包含了我们以上刚讨论过的所有改 变),检查输出结果,确保你理解每一行为什么会产生出来:
$ python scope02.py
ENTER scope: global
Insert: INTEGER
Insert: REAL
Lookup: REAL
Insert: x
Lookup: REAL
Insert: y
Insert: Alpha
ENTER scope: Alpha
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: a
Lookup: INTEGER
Insert: y
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : Alpha
Scope level : 2
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
a: <VarSymbol(name='a', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
LEAVE scope: Alpha
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='REAL')>
y: <VarSymbol(name='y', type='REAL')>
Alpha: <ProcedureSymbol(name=Alpha, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
LEAVE scope: global
关于上面的输出我觉得有几点值得指出:
- 你可以在输出中看到
Insert: INTEGER和Insert: REAL这两行重复了两次,INTEGER和REAL存在于两个作用域(作用域符号表)中:global和Alpha. 原因是我们为每一个作用域都新建了单独的作用域符号表,而符号表会在每 次创建实例的时候初始化内置类型符号。我们会在后面讨论嵌套关系以及它们如何在 代码中表示时修改它。 - 看
Insert: Alpha这一行是如何在ENTER scope: Alpha之前打印的。这只是提 醒一下一个过程的名字所声明的级别,比在其中声明的变量的级别小一级。 - 你可以通过观察打印出的作用域符号表的内容来知道它们包含哪些声明。例如,可以
看到作用域
global中包含了Alpha这个符号。 - 从作用域
global的内容也可以看到,过程Alpha的符号还包含了过程的形参。
在我们运行这个程序之后,内存中的作用域看上去像下面这样,只是两个独立的作用域符 号表:
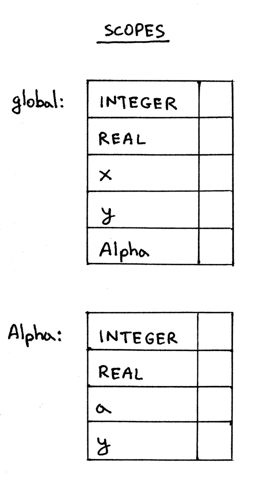
Figure 10: img10
作用域树:作用域符号表链
好了,现在每一个作用域都用一个单独的作用域符号表表示了,但我们又怎样表示作用域
global 和作用域 Alpha 之间,在嵌套关系图里展示的那样的嵌套关系呢?换句话说,
我们怎样在代码中表示作用域 Alpha 是嵌套在作用域 global 之中的呢?答案就是
把这些表链接在一起。
我们会通过在作用域符号表之间创建一个连接来把它们链在一起。这种方式就像一棵树 (我们叫它作用域树),只是有些不同寻常,因为在它之中子结点会指向父结点,而不是 父结点指向子结点。让我们看看下面的作用域树:
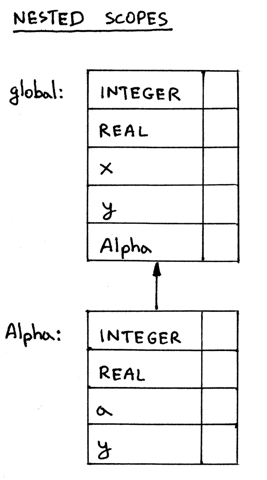
Figure 11: img11
在上面的作用域树中可以看到,作用域 Alpha 通过指向作用域 global 与它连接起
来。换种说法,作用域 Alpha 指向了包含它的作用域,即 global 作用域。这意味
着作用域 Alpha 嵌套于作用域 global 之中。
我们怎样实现作用域链/连接呢?分为两步:
- 我们需要修改
ScopedSymbolTable类,增加一个变量enclosing_scope用来保 存包含该作用域的作用域。这就是上面图中两个作用域之间的连接。 - 我们需要修改
visit_Program和visit_ProcedureDecl这两个方法,使用修改 过的ScopedSymbolTable类来创建一个指向所嵌套于的作用域的真实的连接。
让我们从给 ScopedSymbolTable 类添加 enclosing_scope 字段开始。同时也修改一
下 __init__ 和 __str__ 两个方法。 __init__ 方法会被修改为接收一个新的参
数 enclosing_scope ,它的默认值是 None. __str__ 方法会被修改为输出所包含
于的作用域的名字。下面是修改后 ScopedSymbolTable 类的完整代码:
1 | class ScopedSymbolTable(object): |
现在让我们把注意力放在 visit_Program 上:
1 | def visit_Program(self, node): |
这里有几点值指出和重复说明:
- 我们明确地在创建一个作用域时将
self.current_scope作为enclosing_scope传递。 - 我们将新创建的全局作用域赋值给变量
self.current_scope。 - 我们在将要离开
Program结点之前把变量self.current_scope重置为了它以前 的值。在结束对结点的处理后把current_scope的值重置为以前的值很重要,不然 作用域树的构建会在我们的程序中有多于两个作用域时出问题。我们很快就会看到原 因。
那么,最后,让我们修改 visit_ProcedureDecl 方法:
1 | def visit_ProcedureDecl(self, node): |
同样,相比于 scope02.py 版本主要的变化有:
- 我们明确地在创建一个作用域时将
self.current_scope作用参数enclosing_scope传递。 - 我们不再将一个过程声明的作用域级别硬编进代码了,因为我们可以根据包含该过程 的作用域自动地计算出来:即将包含它的作用域的级别加 1.
- 我们在将要离开
ProcedureDecl结点之前把变量self.current_scope的恢复为 以前的值(对于我们的示例程序来说,以前的值就是全局作用域)。
好了,让看看作用域符号表在经过这些修改后是什么样的。你可以在文件 scope03a.py 中找到所有的改动。我们的示例程序是:
1 | program Main; var x, y: real; procedure Alpha(a : integer); var y : integer; begin end; begin { Main } end. { Main } |
在命令行上运行 scope03a.py 并检查输出结果:
$ python scope03a.py
ENTER scope: global
Insert: INTEGER
Insert: REAL
Lookup: REAL
Insert: x
Lookup: REAL
Insert: y
Insert: Alpha
ENTER scope: Alpha
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: a
Lookup: INTEGER
Insert: y
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : Alpha
Scope level : 2
Enclosing scope: global
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
a: <VarSymbol(name='a', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
LEAVE scope: Alpha
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Enclosing scope: None
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='REAL')>
y: <VarSymbol(name='y', type='REAL')>
Alpha: <ProcedureSymbol(name=Alpha, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
LEAVE scope: global
从上面的输出中可以看到,全局作用域没有包含它的作用域,且包含 Alpha 的作用域
是全局作用域,这正是我们所期望的,因为 Alpha 作用域就是嵌套在全局作用域里的。
现在,如前面承诺的,讨论一下为什么变量 self.current_scope 的赋值和恢复如此重
要。让我们看看下面的程序,它在全局作用域里声明了两个过程:
1 | program Main; var x, y : real; procedure AlphaA(a : integer); var y : integer; begin { AlphaA } end; { AlphaA } procedure AlphaB(a : integer); var b : integer; begin { AlphaB } end; { AlphaB } begin { Main } end. { Main } |
示例程序的嵌套关系图如下:
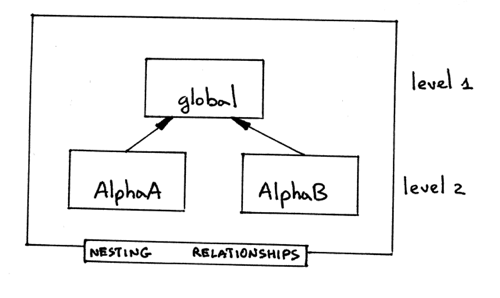
Figure 12: img12
这个程序的 AST 看上去像这样(我只保存了和这个例子相关的部分):
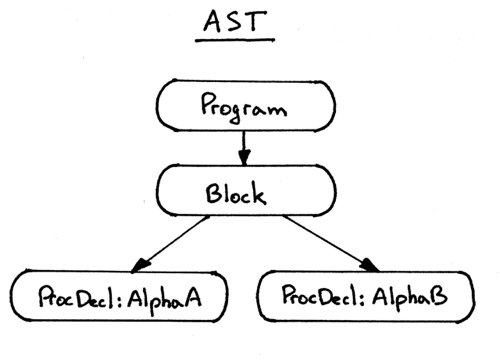
Figure 13: img13
如果我们不在离开 Program 和 ProcedureDecl 结点时恢复当前作用域的值会发生什
么?我们分析一下。
语义分析器遍历树的方式是尝试优先,从左至右,所以它会先遍历结点 AlphaA 对应的
ProcedureDecl 结点,然后再遍历结点 AlphaA 对应的 ProcedureDecl 结点。问
题就是如果我们不在离开 AlphaA 时恢复 self.current_scope 值的话它就会一直指
向 AlphaA 而非全局作用域,结果就是语义分析器会在级别 3 创建作用域 AlphaB,
就好像它是嵌套在作用域 AlphaA 中一样,这当然是不对的。
要看当前作用域在离开 Program 和 ProcedureDecl 结点时没有被恢复这种情况下的
错误行为,下载并在命令行上运行 scope03b.py:
$ python scope03b.py
ENTER scope: global
Insert: INTEGER
Insert: REAL
Lookup: REAL
Insert: x
Lookup: REAL
Insert: y
Insert: AlphaA
ENTER scope: AlphaA
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: a
Lookup: INTEGER
Insert: y
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : AlphaA
Scope level : 2
Enclosing scope: global
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
a: <VarSymbol(name='a', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
LEAVE scope: AlphaA
Insert: AlphaB
ENTER scope: AlphaB
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: a
Lookup: INTEGER
Insert: b
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : AlphaB
Scope level : 3
Enclosing scope: AlphaA
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
a: <VarSymbol(name='a', type='INTEGER')>
b: <VarSymbol(name='b', type='INTEGER')>
LEAVE scope: AlphaB
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Enclosing scope: None
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='REAL')>
y: <VarSymbol(name='y', type='REAL')>
AlphaA: <ProcedureSymbol(name=AlphaA, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
LEAVE scope: global
可以看到,语义分析器中作用域树的构建在存在多于两个作用域时完全是错的:
- 相比于在嵌套关系图中所展示的两个作用域级别,我们有三个
- 全局作用域不包含
AlphaB, 只有AlphaA
要正确的构建一棵作用域树,我们需要遵循一个十分简单的步骤:
- 当进入到一个
Program或ProcedureDecl结点时,创建一个新的作用域,并将 它赋值给self.current_scope. - 当要离开
Program或ProcedureDecl结点时,就将self.current_scope恢 复为进入结点之前的值。
你可以把 self.current_scope 当作一个栈指针,而作用域树就是一组栈:
- 当访问一个
Program或ProcedureDecl结点时,就向栈中压入一个新作用域并 调整栈指针self.current_scope使它指向栈顶,而栈顶此时就是最近入栈的作用 域。 - 当要离开这个结点时,就从栈中弹出一个作用域,并调整栈指针指向栈中前一个作用 域,即新的栈顶作用域。
要观察在多个作用域存在的情况下的正确表现,下载并在命令行上运行 scope03c.py。研 究一下输出。确保你理解发生了什么:
$ python scope03c.py
ENTER scope: global
Insert: INTEGER
Insert: REAL
Lookup: REAL
Insert: x
Lookup: REAL
Insert: y
Insert: AlphaA
ENTER scope: AlphaA
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: a
Lookup: INTEGER
Insert: y
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : AlphaA
Scope level : 2
Enclosing scope: global
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
a: <VarSymbol(name='a', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
LEAVE scope: AlphaA
Insert: AlphaB
ENTER scope: AlphaB
Insert: INTEGER
Insert: REAL
Lookup: INTEGER
Insert: a
Lookup: INTEGER
Insert: b
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : AlphaB
Scope level : 2
Enclosing scope: global
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
a: <VarSymbol(name='a', type='INTEGER')>
b: <VarSymbol(name='b', type='INTEGER')>
LEAVE scope: AlphaB
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Enclosing scope: None
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='REAL')>
y: <VarSymbol(name='y', type='REAL')>
AlphaA: <ProcedureSymbol(name=AlphaA, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
AlphaB: <ProcedureSymbol(name=AlphaB, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
LEAVE scope: global
下面是在运行 scope03c.py 之后作用域符号表的样子,以及正确构建的作用域树:
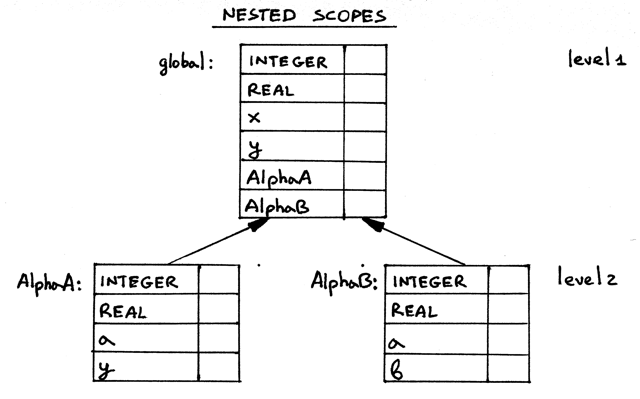
Figure 14: img14
两次强调,我上面已经提到过的,你可以把上面的作用域树想象成一组作用域栈。
现在让我们继续讨论在嵌套作用域存在的情况下 名字解析 如何进行。
嵌套作用域和名字解析
之前我们的关注点在变量和过程声明上。让我们在其中加入变量引用。
下面是一个包含变量引用的示例程序:
1 | program Main; var x, y: real; procedure Alpha(a : integer); var y : integer; begin x := a + x + y; end; begin { Main } end. { Main } |
或者在视觉上增加一些信息:
Figure 15: img08
Figure 16: img09
让我们将注意力放在赋值语句 x := a + x + y; 加上下标后是这样的:
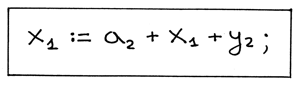
Figure 17: img15
我们看到 x 解析到了级别 1 中的声明, a 解析到了级别 2 中的声明,而 y 也 解析到了级别 2 中的声明。解析是如何进行的呢?让我们看一看。
像 Pascal 这样的词法(静态)作用域语言在解析名字时遵循 最近嵌套作用域 (the most closely nested scope)原则。它的意思是,在每个作用域中,一个名字解析为词法 上最近的声明。对于赋值语句,让我们考察其中的每一个变量引用来看看这条规则在实际 中怎么运行:
因为语义分析器是从赋值语句的右边开始访问的,我们会从算术表达式 a + x + y 中的变量引用 a 开始。我们从词法上最近的作用域开始搜索 a 的声明,也就是 从作用域 Alpha 开始。作用域 Alpha 包含了声明在过程 Alpha 中的变量以及它的形 式参数的声明。我们在作用域 Alpha 中找到了 a 的声明:它是过程 Alpha 的形参 a ── 一个 integer 类型的变量符号。在解析名字时我们通常使用肉眼去看源码 的方式来进行查找(注意, a2 不是变量名,2 只是下标,变量名是 a)。
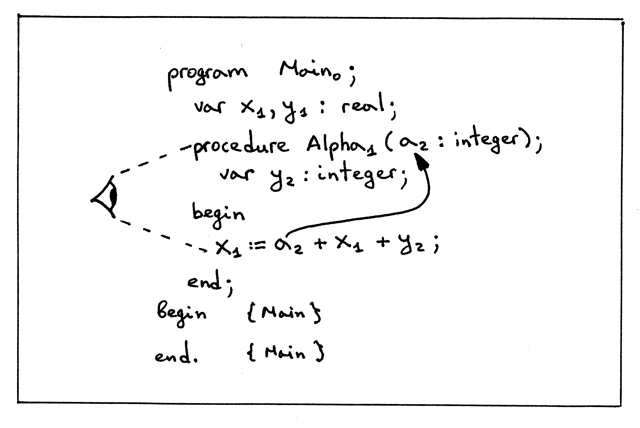
Figure 18: img16
现在来看算术表达式 a + x + y 中对 x 的变量引用。同样,我们首先从词法上 最近的作用域开始搜索 x 的声明。词法上最近的作用域是 Alpha 在级别 2。该作 用域中包含了声明在过程 Alpha 中的变量以及它的形式参数的声明。我们没有在这一 级别的作用域(作用域 Alpha)中找到 x, 因此顺着连接向上找到全局作用域并继 续我们的搜索。我们查找成功了,因为全局作用域中有一个名为 x 的变量符号:
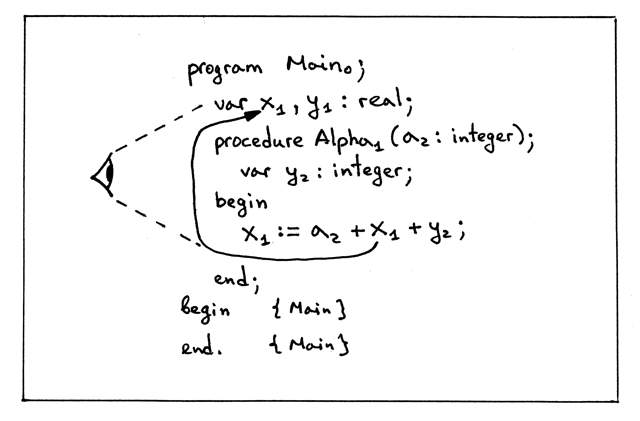
Figure 19: img17
现在,我们看向算术表达式 a + x + y 中的变量引用 y. 我们从词法上最近的作 用域中找到了它的声明,即从作用域 Alpha 中。在作用域 Alpha 中变量 y 是 integer 类型(如果作用域 Alpha 中没有 y 的声明,我们就继续从代码中查找, 会在外一层(全局)作用域中找到 y, 这里它的类型为 real ):
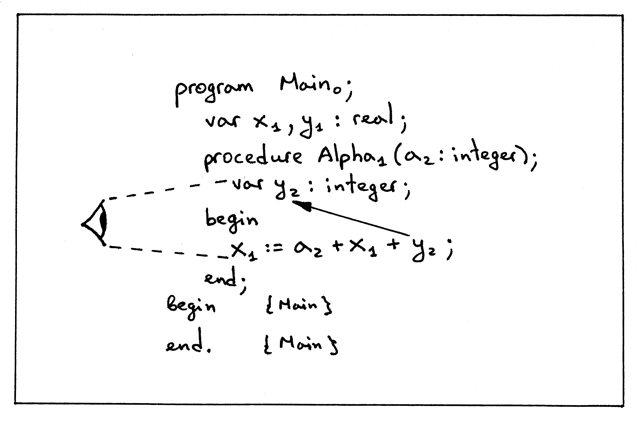
Figure 20: img18
那么,最后,赋值语句 x := a + x + y 左边的变量 x ,它解析到了和右边算术 表达式中的变量引用 x 相同的声明:
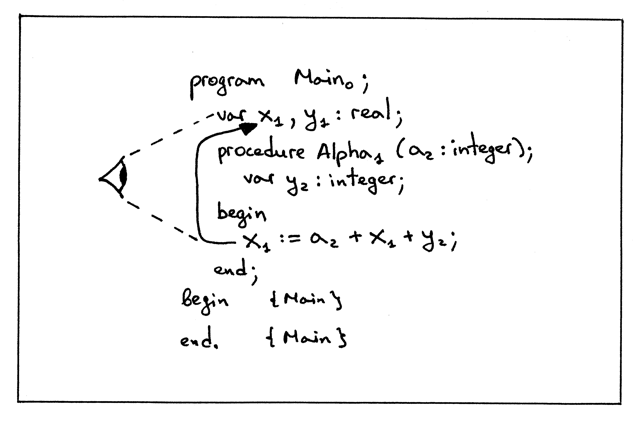
Figure 21: img19
我们怎么实现这样的查找行为呢?先在当前作用域中进行查找,再从外一层的作用域中查
找,一直重复直到找到或者到达了作用域树的最顶层而没有作用域。我们只需要简单地扩
展一下 ScopedSymbolTable 类中的 lookup 方法,使它继续沿着作用域树向上查找
就行了:
1 | def lookup(self, name): |
修改后 lookup 方法的工作方式为:
- 在当前作用域中根据名字来查找符号。如果找到了就返回它。
- 如果没有找到,递归地遍历作用域树,沿着连接从上一级作用域中查找该符号。你不 一定非要用递归的方法进行查找,也可以重写为迭代的方式;重要的是在一个嵌套的 作用域中跟踪到包含它的作用域中,再从那个作用域中查找那个符号,这样一直到找 到它或者你到达了作用域树的顶部,没有更多的作用域可供查找了。
lookup方法还打印出了作用域的名字,放在了括号里,这样就可以在不能在当前作 用域中找到而向上查找时看得更清楚。
让我们看一下在把 lookup 修改为沿作用域树查找之后,语义分析器对示例程序的输出
是什么。下载 scope04a.py 并在命令行上运行它:
$ python scope04a.py
ENTER scope: global
Insert: INTEGER
Insert: REAL
Lookup: REAL. (Scope name: global)
Insert: x
Lookup: REAL. (Scope name: global)
Insert: y
Insert: Alpha
ENTER scope: Alpha
Lookup: INTEGER. (Scope name: Alpha)
Lookup: INTEGER. (Scope name: global)
Insert: a
Lookup: INTEGER. (Scope name: Alpha)
Lookup: INTEGER. (Scope name: global)
Insert: y
Lookup: a. (Scope name: Alpha)
Lookup: x. (Scope name: Alpha)
Lookup: x. (Scope name: global)
Lookup: y. (Scope name: Alpha)
Lookup: x. (Scope name: Alpha)
Lookup: x. (Scope name: global)
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : Alpha
Scope level : 2
Enclosing scope: global
Scope (Scoped symbol table) contents
------------------------------------
a: <VarSymbol(name='a', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
LEAVE scope: Alpha
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Enclosing scope: None
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='REAL')>
y: <VarSymbol(name='y', type='REAL')>
Alpha: <ProcedureSymbol(name=Alpha, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
LEAVE scope: global
检查上面的输出,注意 ENTER 和 Lookup 信息。一些需要注意的点有:
注意语义分析器在插入变量符号 a 之前是怎样查找内置类型
INTEGER的。它先 在当前作用域(Alpha)中搜索INTEGER, 没有找到,然后沿着树向上到了全局作用域, 在那儿找到了:ENTER scope: Alpha Lookup: INTEGER. (Scope name: Alpha) Lookup: INTEGER. (Scope name: global) Insert: a
还要注意语义分析器怎样解析赋值语句 x := a + x + y 中的变量引用的:
Lookup: a. (Scope name: Alpha) Lookup: x. (Scope name: Alpha) Lookup: x. (Scope name: global) Lookup: y. (Scope name: Alpha) Lookup: x. (Scope name: Alpha) Lookup: x. (Scope name: global)
分析器从当前作用域中开始查找,然后沿着树向上到了全局作用域。
让我们看看当 Pascal 程序有一个变量引用不能被解析到变量声明时会发生什么,如下面 的示例程序:
1 | program Main; var x, y: real; procedure Alpha(a : integer); var y : integer; begin x := b + x + y; { ERROR here! } end; begin { Main } end. { Main } |
下载 scope04b.py 并在命令行上运行它:
$ python scope04b.py ENTER scope: global Insert: INTEGER Insert: REAL Lookup: REAL. (Scope name: global) Insert: x Lookup: REAL. (Scope name: global) Insert: y Insert: Alpha ENTER scope: Alpha Lookup: INTEGER. (Scope name: Alpha) Lookup: INTEGER. (Scope name: global) Insert: a Lookup: INTEGER. (Scope name: Alpha) Lookup: INTEGER. (Scope name: global) Insert: y Lookup: b. (Scope name: Alpha) Lookup: b. (Scope name: global) Error: Symbol(identifier) not found 'b'
如你所见,分析器在尝试解析变量引用 b 时首先从作用域 Alpha 找起,然后是全局
作用域,在找不到名字为 b 的符号时,就抛出了语义错误。
很好不错,现在我们知道怎样在程序存在嵌套作用域的情况下,写一个可以分析程序语义 错误的语义分析器了。
源码到源码编译器
现在,说一些完全不同的东西。让我们写一个源码到源码编译器!为什么我们要做这件事? 我们不是在讨论解释器和嵌套作用域吗?是的,但请让我解释一下为什么我觉得在这个时 候学习编写一个源码到源码的编译是个好主意。
首先,让我们聊聊定义。什么是源码到源码编译器?在本文中,我们将一个把由某种语言 编写的程序翻译为同种语言(或几乎相同)程序的编译器叫做 源码到源码编译器.
所以,如果你写了一个翻译器,它将 Pascal 程序作为输入,又输出一个 Pascal 程序, 可能是修改或增强过的,这样的翻译器就被叫做源码到源码编译器。
一个接收 Pascal 程序作为输入,并输出一个类似 Pascal 程序,但为每个名字都加上了 相应作用域级别下标及类型提示的编译器,会是一个供我们学习源码到源码编译器的好的 例子。即我们想要一个源码到源码编译器,它可以接收下面的 Pascal 程序:
1 | program Main; var x, y: real; procedure Alpha(a : integer); var y : integer; begin x := a + x + y; end; begin { Main } end. { Main } |
并将它变成下面这种类 Pascal 程序:
1 | program Main0; var x1 : REAL; var y1 : REAL; procedure Alpha1(a2 : INTEGER); var y2 : INTEGER; begin <x1:REAL> := <a2:INTEGER> + <x1:REAL> + <y2:INTEGER>; end; {END OF Alpha} begin end. {END OF Main} |
下面是我们的源码到源码编译器应该对输入 Pascal 程序进行的修改的列表:
- 每个声明都应该被打印在单独一行,如果我们输入的 Pascal 程序有多个声明,编译
后的输出中每个声明应该在单独一行上。我们可以从上面的例子中看出,这一行代码
var x, y : real;被转换成了多行。 - 每个名字都应该获得一个与相应声明级别相同的下标。
- 每个变量引用,除了要加上下标以外,还应打印成下面的形式:
<var_name_with_subscript:type> - 编译器还应该在每一个块的末尾加上一个注释,形如
{END OF … }, 其中的省略号 会被程序名或过程名替换。这可以帮助我们更快地确认过程的词法边界。
还可以从上面生成的输出中看到,源码到源码编译器也可以帮助理解名字解析的工作方式, 特别是当程序中存在嵌套作用域的时候,因为编译器生成的输出使得我们可以快速地看出 某个变量引用被解析到哪个作用域中的哪个声明。这在学习符号、嵌套作用域和名字解析 时很有用。
我们怎样实现一个这样的源码到源码编译器呢?其实我们已经讨论过了所有必要的部分。 我们需要做的就是对语义分析器做一些扩展来生成输出。你可以在这儿看到完整的编译器 源码。它基本上就是加了些料的语义分析器,修改为了为特定 AST 结点生成和返回字符 串。
下载 src2srccompiler.py,研究它,并尝试输入不同的 Pascal 程序作为输入。
例如,对于下面的程序来说:
1 | program Main; var x, y : real; var z : integer; procedure AlphaA(a : integer); var y : integer; begin { AlphaA } x := a + x + y; end; { AlphaA } procedure AlphaB(a : integer); var b : integer; begin { AlphaB } end; { AlphaB } begin { Main } end. { Main } |
这个编译器会生成下面的输出:
1 | $ python src2srccompiler.py nestedscopes03.pas program Main0; var x1 : REAL; var y1 : REAL; var z1 : INTEGER; procedure AlphaA1(a2 : INTEGER); var y2 : INTEGER; begin <x1:REAL> := <a2:INTEGER> + <x1:REAL> + <y2:INTEGER>; end; {END OF AlphaA} procedure AlphaB1(a2 : INTEGER); var b2 : INTEGER; begin end; {END OF AlphaB} begin end. {END OF Main} |
真酷,恭喜,现在你知道怎样写一个基本的源码到源码编译器了!
使它来加深你对嵌套作用域、名字解析的理解,以及当你有一棵 AST 和一个程序的符号 表时可以做什么。
现在我们有了一个有用的工具来帮助我们为程序添加下标,让我们看一个大一点的嵌套作 用域的例子,你可以在 nestedscopes04.pas 中找到它:
1 | program Main; var b, x, y : real; var z : integer; procedure AlphaA(a : integer); var b : integer; procedure Beta(c : integer); var y : integer; procedure Gamma(c : integer); var x : integer; begin { Gamma } x := a + b + c + x + y + z; end; { Gamma } begin { Beta } end; { Beta } begin { AlphaA } end; { AlphaA } procedure AlphaB(a : integer); var c : real; begin { AlphaB } c := a + b; end; { AlphaB } begin { Main } end. { Main } |
下面是程序声明的作用域、嵌套关系图,以及作用域信息表:
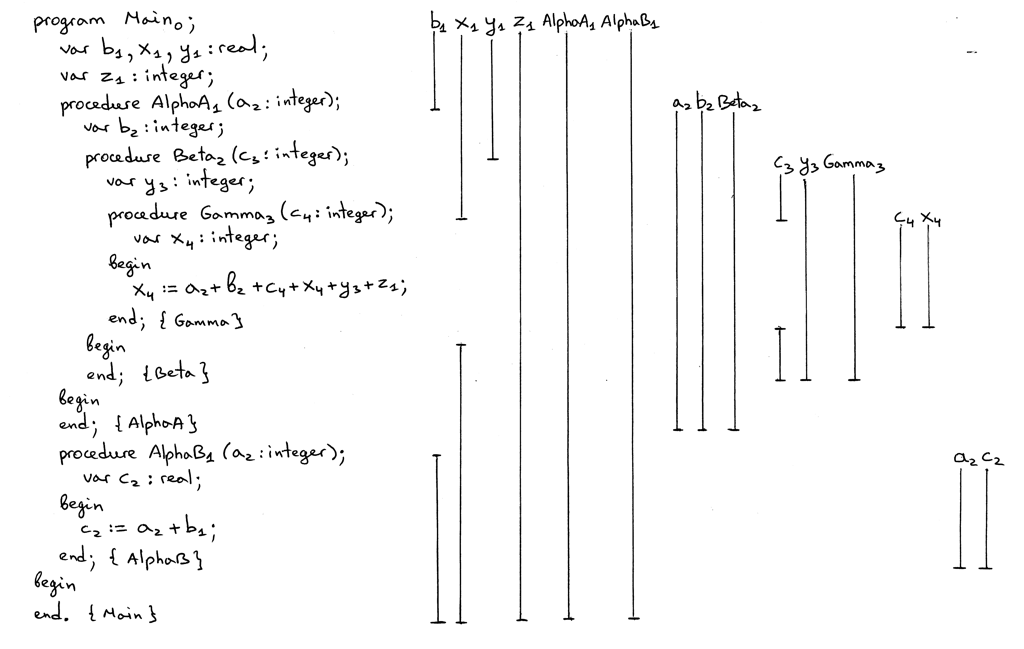
Figure 22: img20
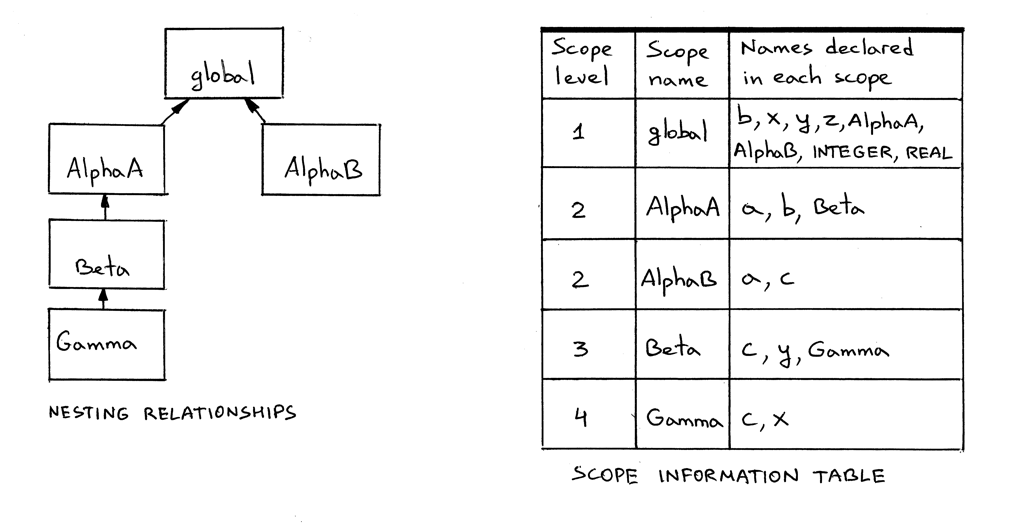
Figure 23: img21
让我们运行一下源码到源码编译器并检查它的输出。它的下标应该和上面图片中作用域信 息表中的一致:
1 | $ python src2srccompiler.py nestedscopes04.pas program Main0; var b1 : REAL; var x1 : REAL; var y1 : REAL; var z1 : INTEGER; procedure AlphaA1(a2 : INTEGER); var b2 : INTEGER; procedure Beta2(c3 : INTEGER); var y3 : INTEGER; procedure Gamma3(c4 : INTEGER); var x4 : INTEGER; begin <x4:INTEGER> := <a2:INTEGER> + <b2:INTEGER> + <c4:INTEGER> + <x4:INTEGER> + <y3:INTEGER> + <z1:INTEGER>; end; {END OF Gamma} begin end; {END OF Beta} begin end; {END OF AlphaA} procedure AlphaB1(a2 : INTEGER); var c2 : REAL; begin <c2:REAL> := <a2:INTEGER> + <b1:REAL>; end; {END OF AlphaB} begin end. {END OF Main} |
花此时间研究一下图片和源码到源码编译器的输出。确保你理解了下面这些主要的点:
- 怎样用竖线来表示声明的作用域的。
- 作用域断开的部分表示一个变量在嵌套的作用域中被重新声明了。
AlphaA和AlphaB是在全局作用域中声明的。AlphaA和AlphaB的声明引入了新的作用域。- 作用域是如何互相嵌套的,以及它们的嵌套关系。
- 为什么不同的名字,以及它们在在赋值语句中的变量引用,是这样的下标。换句话说,
名字解析是怎样进行的,特别是链接在一起的作用域符号表中的
lookup方法是怎么 工作的。
再运行一下下面这个程序:
1 | $ python scope05.py nestedscopes04.pas |
检查作用域符号表链的内容,并将它与上面图片中的作用域信息相比较。别忘了 genastdot.py,你可以用它来生成 AST 的图形来查看过程是如何互相嵌套的。
在我们结束我们今天关于嵌套作用域的讨论之前,回忆一下之前我们移除了语义检查中对
源程序中重复标识符的检查。让我们把它找回来。为了使这个检查能在嵌套作用域和新的
lookup 方法下工作,我们需要做些修改。首先,我们需要修改 lookup 方法,增加
一个参数来让我们的搜索限定在当前作用域下:
1 | def lookup(self, name, current_scope_only=False): |
然后,我们需要修改 visit_VarDecl 方法,并通过 lookup 方法中的参数
current_scope_only 来添加我们的检查:
1 | def visit_VarDecl(self, node): |
如果我们不把对重复标识符的搜索限定在当前作用域,就可能会在外层作用域中找到一个 相同名字的变量符号,结果就会在实际没有语义错误时抛出一个错误。
下面是 scope05.py 与一个没有重复标识符错误的程序产生的输出。注意下面的输出中有 更多的行,因为我们检查重复标识符的行为会在插入一个新标识符之前进行:
$ python scope05.py nestedscopes02.pas
ENTER scope: global
Insert: INTEGER
Insert: REAL
Lookup: REAL. (Scope name: global)
Lookup: x. (Scope name: global)
Insert: x
Lookup: REAL. (Scope name: global)
Lookup: y. (Scope name: global)
Insert: y
Insert: Alpha
ENTER scope: Alpha
Lookup: INTEGER. (Scope name: Alpha)
Lookup: INTEGER. (Scope name: global)
Insert: a
Lookup: INTEGER. (Scope name: Alpha)
Lookup: INTEGER. (Scope name: global)
Lookup: y. (Scope name: Alpha)
Insert: y
Lookup: a. (Scope name: Alpha)
Lookup: x. (Scope name: Alpha)
Lookup: x. (Scope name: global)
Lookup: y. (Scope name: Alpha)
Lookup: x. (Scope name: Alpha)
Lookup: x. (Scope name: global)
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : Alpha
Scope level : 2
Enclosing scope: global
Scope (Scoped symbol table) contents
------------------------------------
a: <VarSymbol(name='a', type='INTEGER')>
y: <VarSymbol(name='y', type='INTEGER')>
LEAVE scope: Alpha
SCOPE (SCOPED SYMBOL TABLE)
===========================
Scope name : global
Scope level : 1
Enclosing scope: None
Scope (Scoped symbol table) contents
------------------------------------
INTEGER: <BuiltinTypeSymbol(name='INTEGER')>
REAL: <BuiltinTypeSymbol(name='REAL')>
x: <VarSymbol(name='x', type='REAL')>
y: <VarSymbol(name='y', type='REAL')>
Alpha: <ProcedureSymbol(name=Alpha, parameters=[<VarSymbol(name='a', type='INTEGER')>])>
LEAVE scope: global
现在,让我们再测试一下 scope05.py,看它怎么捕捉到一个重复标签符语义错误。
例如,对于下面存在错误的程序来说,在作用域 Alpha 中有一个重复声明 a:
1 | program Main; var x, y: real; procedure Alpha(a : integer); var y : integer; var a : real; { ERROR here! } begin x := a + x + y; end; begin { Main } end. { Main } |
这个程序产生了下面的输出:
$ python scope05.py dupiderror.pas ENTER scope: global Insert: INTEGER Insert: REAL Lookup: REAL. (Scope name: global) Lookup: x. (Scope name: global) Insert: x Lookup: REAL. (Scope name: global) Lookup: y. (Scope name: global) Insert: y Insert: Alpha ENTER scope: Alpha Lookup: INTEGER. (Scope name: Alpha) Lookup: INTEGER. (Scope name: global) Insert: a Lookup: INTEGER. (Scope name: Alpha) Lookup: INTEGER. (Scope name: global) Lookup: y. (Scope name: Alpha) Insert: y Lookup: REAL. (Scope name: Alpha) Lookup: REAL. (Scope name: global) Lookup: a. (Scope name: Alpha) Error: Duplicate identifier 'a' found
它如期望捕捉到了错误。
趁着这个好的结果,让我们结束今天关于作用域,作用域符号表和嵌套作用域的讨论。
总结
我们讨论了好多基础。让我们快速地回顾一下在这篇文章中都学了什么:
- 我们学习了作用域,它们为什么有用,以及怎么用代码实现它们。
- 我们学习了嵌套作用域,以及如何作用作用域符号表链来实现嵌套作用域。
- 我们学习了怎样编写一个语义分析器,它在遍历 AST 的同时,构建了作用域符号表, 并将它们链接在一起,还做了各种语义检查。
- 我们学习了名字解析以及语义分析器怎样使用链接在一起的作用域符号表将名字解析到
它们的声明,以及
lookup方法怎样沿着作用域树向上根据某个名字递归查找一个声 明。 - 我们学习了在语义分析器中构建一个作用域树,包括了遍历 AST,在进入一个特定的 AST 结点时在作用域符号表栈上“压入”一个新作用域,在离开时再从栈顶“弹出”它,使 作用域树看上去像一个作用域符号表栈的集合。
- 我们学习了怎样编写一个源码到源码编译器,它在学习嵌套作用域、作用域级别和名字 解析时是一个很有用的工具。
练习
练习时间,Oh yeah!
Figure 24: img22
- 你已经在本文的图片中看到了,程序声明中的名字
Main的下标是 0。我也提到过 程序名不在全局作用域中,而是在级别为0的更外一层。扩展 spi.py 增加一个新的内 置作用域,使它在级别0上,并把内置类型INTEGER和REAL移到这个作用域中。 为了有趣和练习的目的,你也可以修改代码把程序名也放进那个作用域中。 - 对于文件 nestedscopes04.pas 做下面的事件:
- 把 Pascal 源程序写在一张纸上
- 为程序中的每个名字标上下标,表示出这个名字解析到的声明所在的作用域。
- 为每个名字声明(变量和过程)画出竖线表示出它的作用域。在画的时候别忘了作 用域空档和它们的含义。
- 为这个程序编写一个源码到源码编译器,还要参考本文中的实现。
- 使用原来的程序 src2srccompiler.py 来验证你的编译器的输出,以及你是否在练 习2.2标对了下标。
- 修改源码到源码编译器,为内置类型
INTEGER和REAL标明下标 去掉 spi.py 中下面代码块的注释符号
1
2
3
4
5
6# interpreter = Interpreter(tree)
# result = interpreter.interpret()
# print('')
# print('Run-time GLOBAL_MEMORY contents:')
# for k, v in sorted(interpreter.GLOBAL_MEMORY.items()):
# print('%s = %s' % (k, v))把文件 part10.pas 作为输入运行这个解释器:
1
$ python spi.py part10.pas
指出问题并在语义分析器中加入缺少的方法。
这就是今天所有的内容。下一篇文章中我们会学习运行时,调用栈,实现过程调用,以及 编写我们第一个版本的递归阶乘函数。敬请关注,下次再见!
如果你有兴起,下面是我准备这篇文章时参考的书(推广链接):
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Engineering a Compiler, Second Edition
- Programming Language Pragmatics, Fourth Edition
- Compilers: Principles, Techniques, and Tools (2nd Edition)
- Writing Compilers and Interpreters: A Software Engineering Approach
本系列的所有文章:
- Let’s Build A Simple Interpreter. Part 1.
- Let’s Build A Simple Interpreter. Part 2.
- Let’s Build A Simple Interpreter. Part 3.
- Let’s Build A Simple Interpreter. Part 4.
- Let’s Build A Simple Interpreter. Part 5.
- Let’s Build A Simple Interpreter. Part 6.
- Let’s Build A Simple Interpreter. Part 7.
- Let’s Build A Simple Interpreter. Part 8.
- Let’s Build A Simple Interpreter. Part 9.
- Let’s Build A Simple Interpreter. Part 10.
- Let’s Build A Simple Interpreter. Part 11.
- Let’s Build A Simple Interpreter. Part 12.
- Let’s Build A Simple Interpreter. Part 13.
- Let’s Build A Simple Interpreter. Part 14.