原文地址:Let’s Build A Simple Interpreter. Part 9.
我记得当我还在大学时(很久以前)学习系统编程,我相信唯一“真正”的语言就是汇编和 C。 而 Pascal 则是──怎么说得好听点──非常高级的语言,被不想知道底层工作方式的应用程序 开发者使用。
我那时一点也不知道我为了付账单而写几乎所有东西会是用 Python (且喜欢它的所有一 切),以及我会因为在本系列第一篇文章中提到的原因写一个 Pascal 解释器和编译器。
这些天,我认为自己是一个编程语言爱好者,而且我被所有编程语言及他们独一无二的特点 所吸引。话说回来,我不得不说明我更喜欢某些语言多过其他的。我是偏心的且我会是第一 个承认这点的人。:)
这是以前的我:
Figure 1: story before
而现在:
Figure 2: story now
好了,让我们开始干活。下面是你今天会学习的:
- 怎样解析和解释一个 Pascal 程序定义。
- 怎样解析和解释一个复合语句。
- 如何解析和解释赋值语句,还有变量。
- 一点关于符号表的知识以及如何存储及查找变量。
我会使用下面的类 Pascal 示例程序来引入新的概念:
1 | BEGIN BEGIN number := 2; a := number; b := 10 * a + 10 * number / 4; c := a - - b END; x := 11; END. |
你可以说这相比于跟随本系列前面的文章所写的命令行解释器是很大的一步,但我希望这是 带给你兴奋的一步。它不再“只是”一个计算机了,我们正在越来越正经,像 Pascal 那样正 经。
让我们深入进去看看新语言结构的句法图及他们相应的语法规则。
各就各位:预备,出发!
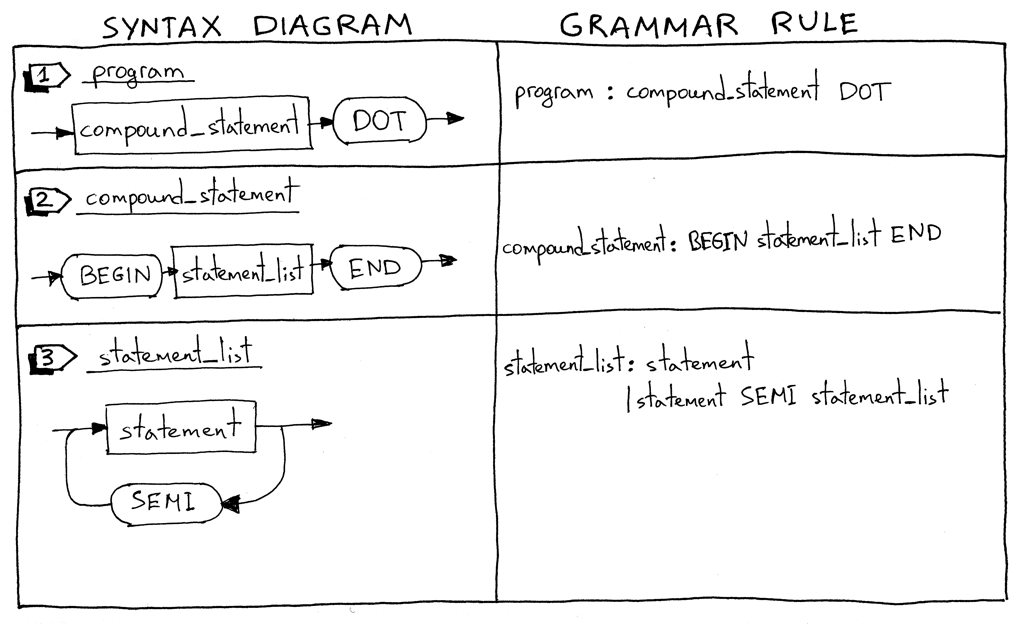
Figure 3: syntax diagram 01
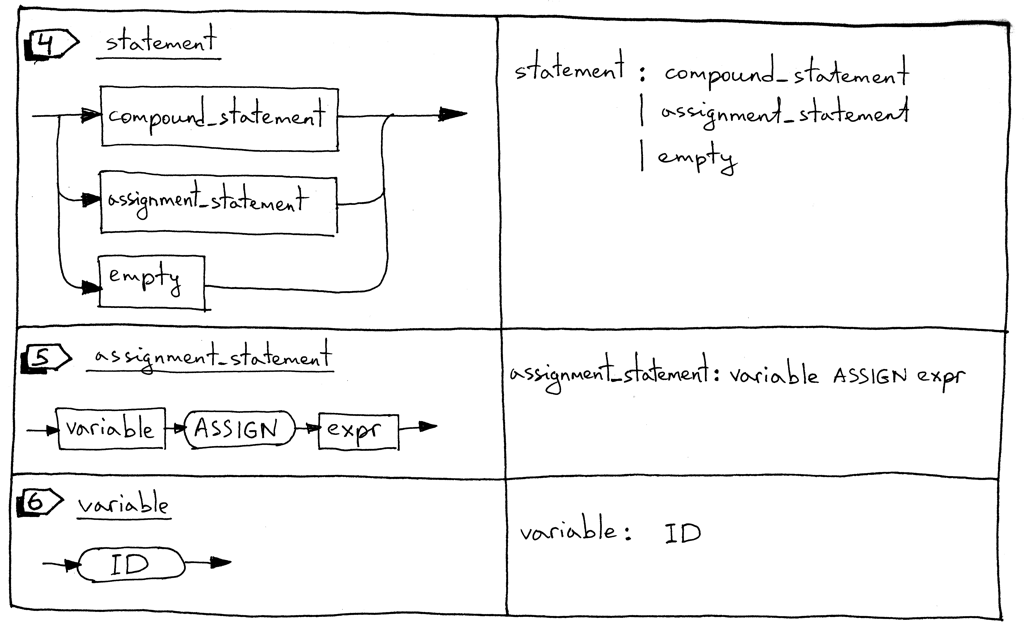
Figure 4: syntax diagram 02
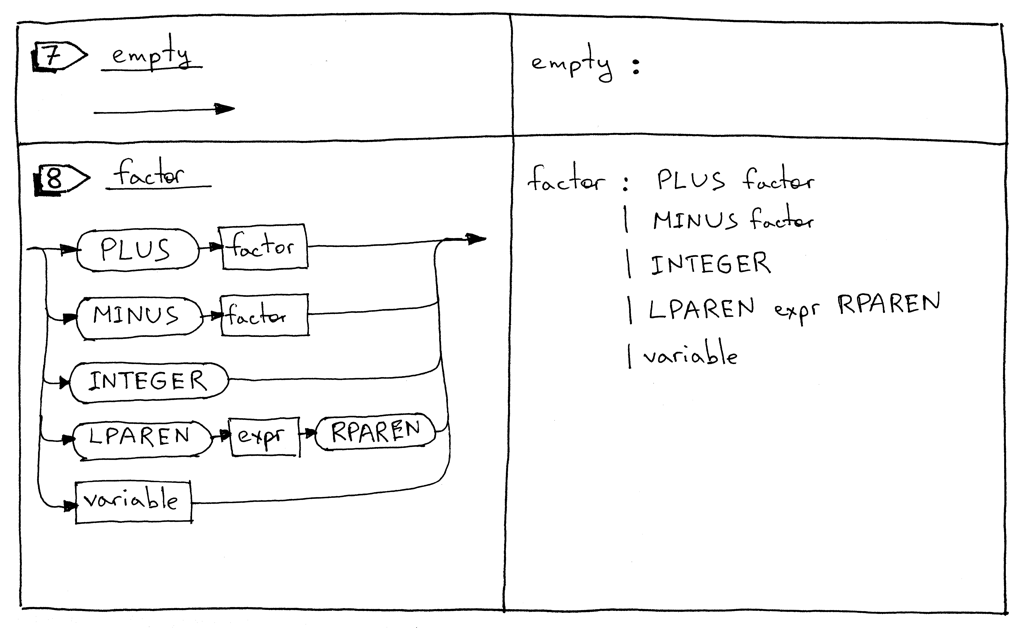
Figure 5: syntax diagram 03
我会从描述什么是一个 Pascal
program开始。一个 Pascal program 由一个点号 结尾的复合语句组成。下面是一个 program 的例子:"BEGIN END."
我要提醒一下这并不是一个完整的 program 定义,我们会在本系列的后续扩展它。
什么是复合语句(compound statement)? compound statement 是一个由 BEGIN 和 END 标识的块,可以包含一组(可能为空)语句,这些语句也可能是复合语句。复合语 句中的每条语句,除了最后一条,都必须以一个分号结尾。块中的最后一条语句可以包 含或不包含结尾分号。这里是一些合法的复合语句:
"BEGIN END" "BEGIN a := 5 x := 11 END" "BEGIN a := 5 x := 11; END" "BEGIN BEGIN a := 5 END; x := 11 END"
- statement list 是一列在复合语句中的 0 或多个语句。参考上面的例子。
- statement 可以是一个复合语句,一个赋值语句,也可以是一个空语句。
assignment statement 是一个变量后跟一个 ASSIGN token (两个字符,‘:’和‘=’) 后再跟一个表达式。
"a := 11" "b := a + 9 - 5 * 2"
variable 是一个标识符。我们使用 ID token 表示变量。token 的值是该变量的名字如 ‘a’,‘number’等。在下面的代码块中‘a’和‘b’是变量:
"BEGIN a := 11; b := a + 9 - 5 * 2 END"
- empty 语句表示一个没有更多产生式的语法规则。我们在 parser 中用空语句语法规则来 标志语句列表的结束及允许复合语句中为空如 ‘BEGIN END’。
- factor 规则被修改为处理变量。
现在让我们看一眼完整的语法:
program : compound_statement DOT
compound_statement : BEGIN statement_list END
statement_list : statement
| statement SEMI statement_list
statement : compound_statement
| assignment_statement
| empty
assignment_statement : variable ASSIGN expr
empty :
expr : term ((PLUS | MINUS) term)*
term : factor ((MUL | DIV) factor)*
factor : PLUS factor
| MINUS factor
| INTEGER
| LPAREN expr RPAREN
| variable
variable : ID
你可能注意到了我没有在 compound_statement 规则中使用星号‘*’这个符号来表示 0 或
多次重复,而是明确地定义了 statement_list 规则。这是表示‘0或多次’操作的另一种
方式,当我们学到像本系列后面的 PLY parser 生成器时会很有用。我还把 “(PLUS |
MINUS) factor” (一元操作符)子规则分成了两条规则。
为了支持更新后的语法,我们需要对我们的 lexer, parser 和 interpreter 做一些修改。 让一个一个地看一下这些修改。
下面是是我们 lexer 修改的概要:
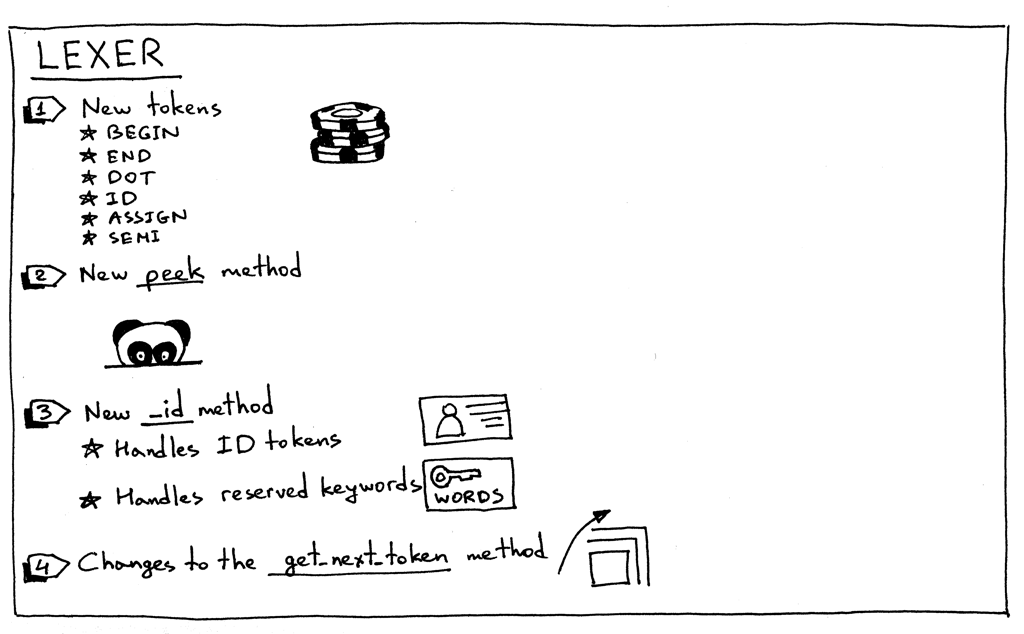
Figure 6: lexer
- 为了支持 Pascal 的 program 定义,以及 compound statement, assignment
statement 和 variable,我们的 lexer 需要返回新的 token:
- BEGIN (标识 compound statement 的开始)
- END (标识 compound statement 的结束)
- DOT (代表点字符‘.’的 token,pascal 的 program 定义需要它)
- ASSIGN (代表两个字符序列‘:=’的 token)。在 Pascal 中,赋值操作符和其他许多语 言不同,如 C, Python, Java, Rust, Go 等,在这些语言中赋值使用单个字符‘=’表 示。
- SEMI (代表分号字符‘;’的 token,用来在 compound statement 中标识一条 statement 的结束)
- ID (代表合法标识符的 token。标识符由字母开头,后跟任意数量的字母或数字)
有时,为了能够区分由相同字符开始的不同 token (‘:’与‘:=’ 或者 ‘==’与‘=>’),我 们需要在不消耗下一个字符的情况下看一下输入内容。为了这个目的,我引入了
peek方法来帮助我们确认赋值语句。该方法并不是严格必须的,但我需要在本系列较早的地 方引入它,而且它会使得get_next_token方法更简洁。peek所做的就是从缓冲 区中返回下一个字符而不递增self.pos变量。下面就是该方法:1
2
3
4
5
6def peek(self):
peek_pos = self.pos + 1
if peek_pos >= len(self.text):
return None
else:
return self.text[peek_pos]因为 Pascal 变量和保留关键字都是标识符,我们会在一个方法
_id中处理它们。它 的工作方式是 lexer 消耗一个字母数字序列然后查看它是否是保留字。如果是,就返回 一个为该关键字预先构建好的 token。如果不是,就返回一个新的 ID token,它的值就 是所消耗的字符串(lexeme)。我打赌你现在肯定在想:“天呐,给我看代码。”:)给:1
2
3
4
5
6
7
8
9
10
11
12
13
14RESERVED_KEYWORDS = {
'BEGIN': Token('BEGIN', 'BEGIN'),
'END': Token('END', 'END'),
}
def _id(self):
"""Handle identifiers and reserved keywords"""
result = ''
while self.current_char is not None and self.current_char.isalnum():
result += self.current_char
self.advance()
token = RESERVED_KEYWORDS.get(result, Token(ID, result))
return token现在我们来看一看 lexer 中的主要方法
get_next_token的变化:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def get_next_token(self):
while self.current_char is not None:
...
if self.current_char.isalpha():
return self._id()
if self.current_char == ':' and self.peek() == '=':
self.advance()
self.advance()
return Token(ASSIGN, ':=')
if self.current_char == ';':
self.advance()
return token(SEMI, ';')
if self.current_char == '.':
self.advance()
return Token(DOT, '.')
...
是时候看一下我们的新 lexer 发光发亮了。从 GitHub 下载源代码且从保存 spi.py 文件 相同的目录运行 Python shell:
1 | >>> from spi import Lexer |
继续看一下 parser 的变化。
下面是是我们 parser 修改的概要:
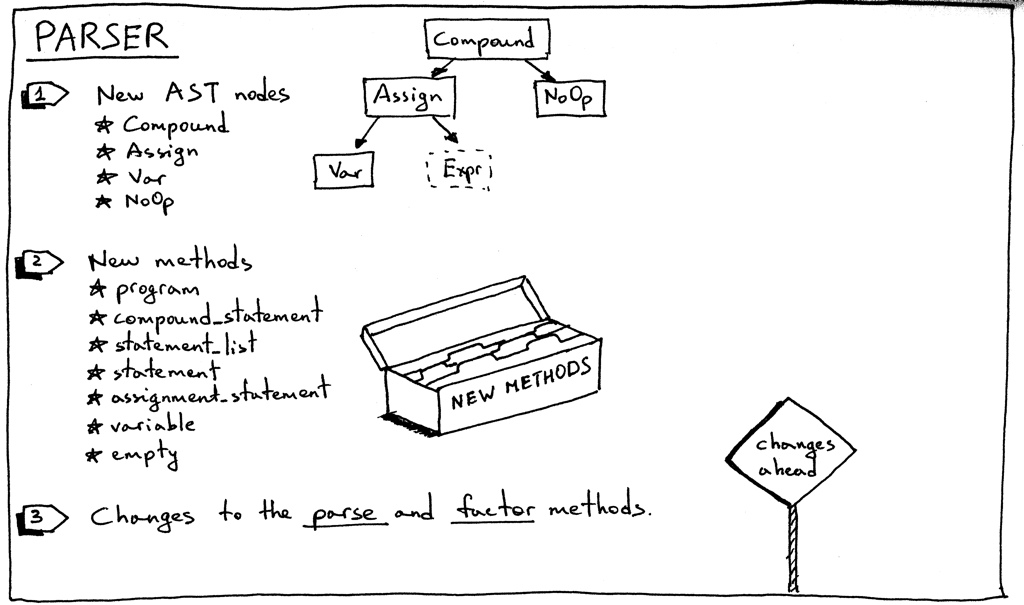
Figure 7: parser
- 我们从新的 AST 结点开始:
AST 结点
Compound代表了一个 compound statement。它在变量children包含 了一列 statement 结点。1
2
3
4class Compound(AST):
"""Represents a 'BEGIN ... END' block"""
def __init__(self):
self.children = []AST 结点
Assign代表了一个 assignment statement。它的left变量保存了一 个Var结点而right变量保存了一个expr方法返回的结点:1
2
3
4
5class Assign(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = rightAST 结点
Var代表了一个变量(你猜对了)。self.value保存了变量的名字。1
2
3
4
5class Var(AST):
"""The Var node is constructed out of ID token."""
def __init__(self, token):
self.token = token
self.value = token.value结点
NoOp被用来代表一个 empty 语句。例如‘BEGIN END’是一个没有语句的合法 compound statement。1
2class NoOp(AST):
pass
如你所记,语法中的每条规则在我们的递归下降 parser 中都有相应的方法。这次我们 会添加 7 个新方法。这些方法负责解析新语言结构及构建新的 AST 结点。他们都很直 接:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73def program(self):
"""program : compound_statement DOT"""
node = self.compound_statement()
self.eat(DOT)
return node
def compound_statement(self):
"""
compound_statement : BEGIN statement_list END
"""
self.eat(BEGIN)
nodes = self.statement_list()
self.eat(END)
root = Compound()
for node in nodes:
root.children.append(node)
return root
def statement_list(self):
"""
statement_list : statement
| statement SEMI statement_list
"""
node = self.statement()
results = [node]
while self.current_token.type == SEMI:
self.eat(SEMI)
results.append(self.statement())
if self.current_token.type == ID:
self.error()
return results
def statement(self):
"""
statement : compound_statement
| assignment_statement
| empty
"""
if self.current_token.type == BEGIN:
node = self.compound_statement()
elif self.current_token.type == ID:
node = self.assignment_statement()
else:
node = self.empty()
return node
def assignment_statement(self):
"""
assignment_statement : variable ASSIGN expr
"""
left = self.variable()
token = self.current_token
self.eat(ASSIGN)
right = self.expr()
node = Assign(left, token, right)
return node
def variable(self):
"""
variable : ID
"""
node = Var(self.current_token)
self.eat(ID)
return node
def empty(self):
"""An empty production"""
return NoOp()我们还需要更新现在的
factor方法来解析变量:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def factor(self):
"""factor : PLUS factor
| MINUS factor
| INTEGER
| LPAREN expr RPAREN
| variable
"""
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
node = UnaryOp(token, self.factor())
return node
...
else:
node = self.variable()
return nodeparser 的
parse方法更新为了从解析一个 program 开始:1
2
3
4
5
6def parse(self):
node = self.program()
if self.current_token.type != EOF:
self.error()
return node
下面再看一下我们的例子程序:
1 | BEGIN BEGIN number := 2; a := number; b := 10 * a + 10 * number / 4; c := a - - b END; x := 11; END. |
让我们用 genastdot.py 来看一下(为了简洁,当显示 Var 结点时,仅显示结点的变量
名,而显示 Assign 结点时会显示 ‘:=’ 而非字符串‘Assign’):
1 | $ python genastdot.py assignments.txt > ast.dot && dot -Tpng -o ast.png ast.dot |
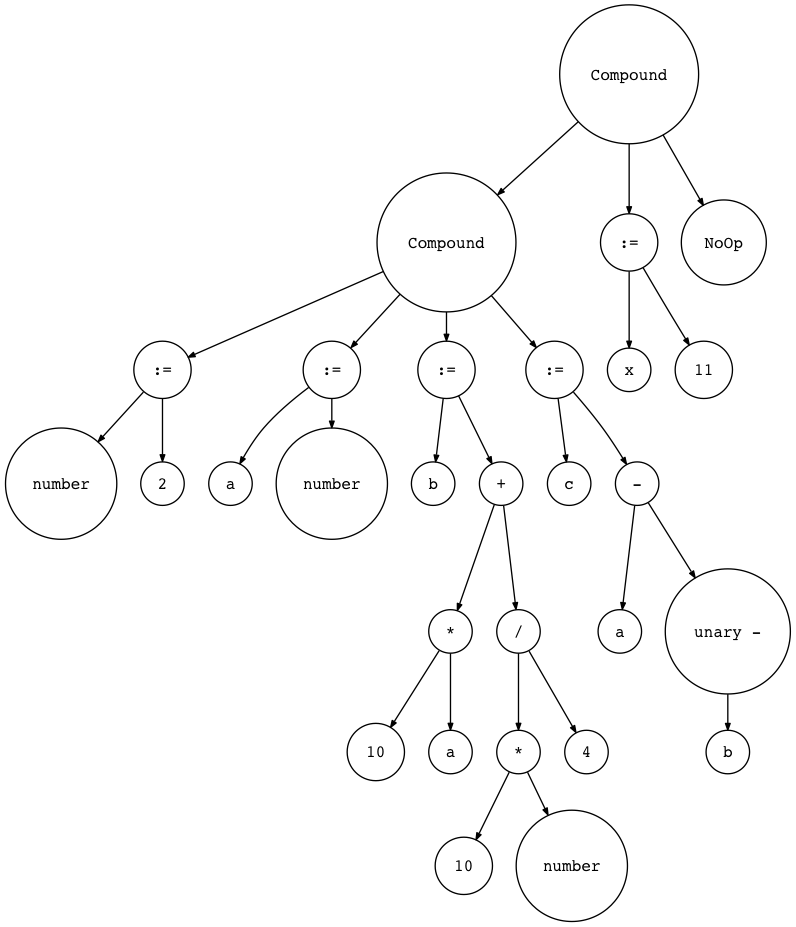
Figure 8: full ast
最后,是 interpreter 需要修改的地方:
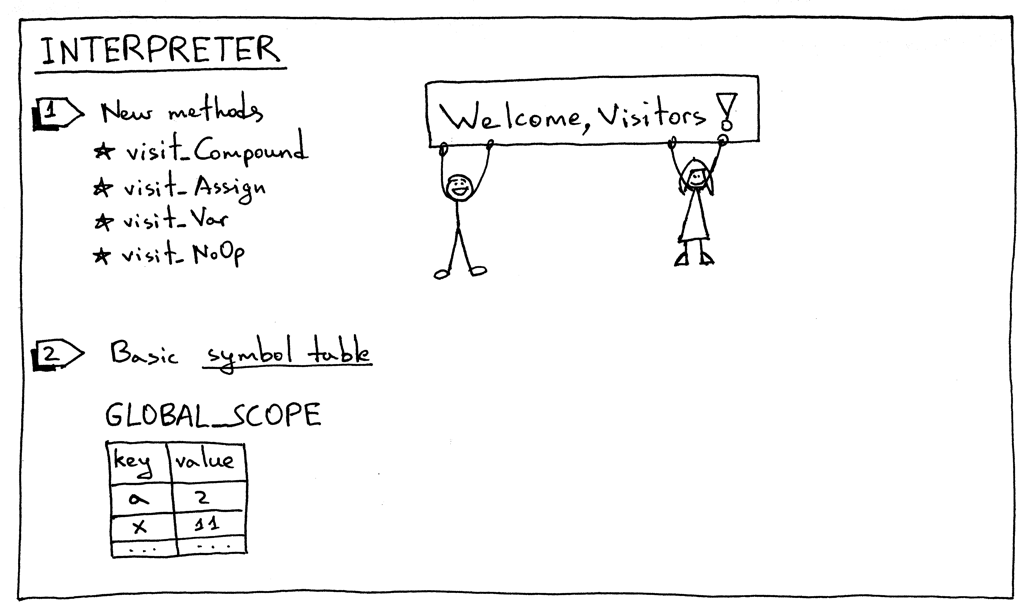
Figure 9: interpreter
为了解释新的 AST 结点,我们为 interpreter 需要添加相应的 visitor 方法。一共有
4 个新方法:
- visitCompound
- visitAssign
- visitVar
- visitNoOp
Compound 和 NoOp 的 visitor 方法很直接。 visit_Compound 方法会遍历它的子结
点并挨个访问它们,而 visit_NoOp 方法什么也不做。
1 | def visit_Compound(self, node): |
Assign 和 Var 的 visitor 方法需要详细地考查一下。
当我们向一个变量赋值时,需要将该值保存在某个地方以供稍后使用,而这正是
visit_Assign 方法要做的:
1 | def visit_Assign(self, node): |
这个方法保存了一个键值对(变量名和与之相关的值)到一个名为 GLOBAL_SCOPE 符号表
中。什么是符号表(symbol table)? 符号表 是一个用来跟踪源代码中各种符号的抽象数
据类型。我们现在仅有的符号类型就是变量,我们会用 Python 的字典来实现符号表。现在
我只能说明符号表在本文中被使用的方式有些“将就”:它不是一个包含特殊方法的单独的
类,而是简单地用了一个 Python 字典,它还承担了内存空间的任务。在未来的文章中,我
会更详细地谈论符号表,那时我们会移除所有这些权宜之处。
让我们看一下语句“a := 3;”的 AST 以及在调用 visit_Assign 方法后的符号表:
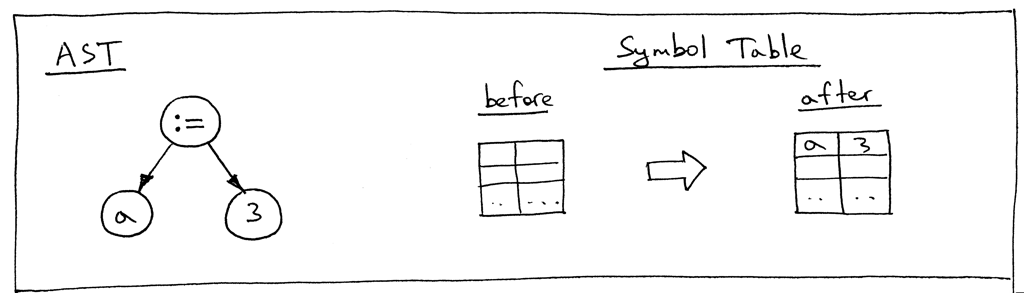
Figure 10: ast st01
现在我们来看一看语句“b := a + 7;”的 AST
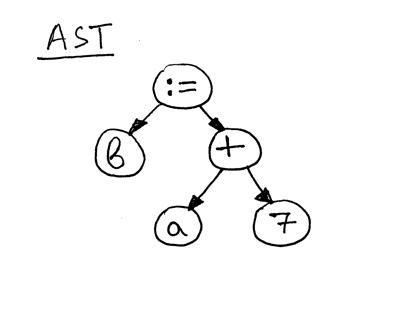
Figure 11: ast only st02
如你所见,赋值语句的右边“a+7”引用了变量‘a’,因此在对表达式“a+7”求值之前需要找到
‘a’的值,而这是方法 visit_Var 的职责:
1 | def visit_Var(self, node): |
当该方法如上图所示访问一个 Var 结点时,首先得到变量名,然后把该名字当作键值从
GLOBAL_SCOPE 字典中得到变量的值。如果它找到了值,就返回它,如果没有找到,就抛
出一个异常。下面是符号表在对赋值表达式“b := a + 7;”进行求值之前的内容:
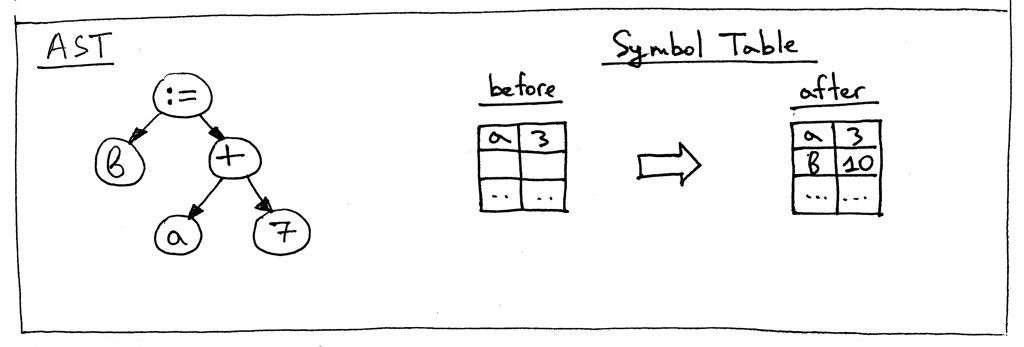
Figure 12: ast st02
这些就是今天为了实现 interpreter 新功能所要做的所有改动。在主程序结束时,我们简
单地把符号表 GLOBAL_SCOPE 的内容打印到标准输出。
让我们带着更新后的 interpreter 在 Python shell 和命令行上跑一跑。确保在测试之前 下载了 interpreter 的源代码和文件 assignments.txt:
启动你的 Python shell:
1 | $ python |
使用命令行时,把源文件当作输入传给我们的 interpreter:
1 | $ python spi.py assignments.txt {'a': 2, 'x': 11, 'c': 27, 'b': 25, 'number': 2} |
如果你还没有尝试过,自己试一试,确认 interpreter 可以正确工作。
让我们总结一下为了把 Pascal 解释器扩展为本文中的样子我们必须做什么:
- 增加新的语法规则
- 增加新的 token 以及在 lexer 中增加支持方法并更新
get_next_token方法 - 在 parser 中为新的语言结构增加新的 AST 结点
- 根据新的语法规则向我们的递归下降 parser 增加新的方法,且在需要时(
factor方 法,就是你:)更新现有的方法 - 向 interpreter 添加新的 visitor 方法
- 增加一个字典来保存变量并进行查找
在这一部分中我不得不引入一些“权宜之处”,在本系列后面我们会将它们移除:
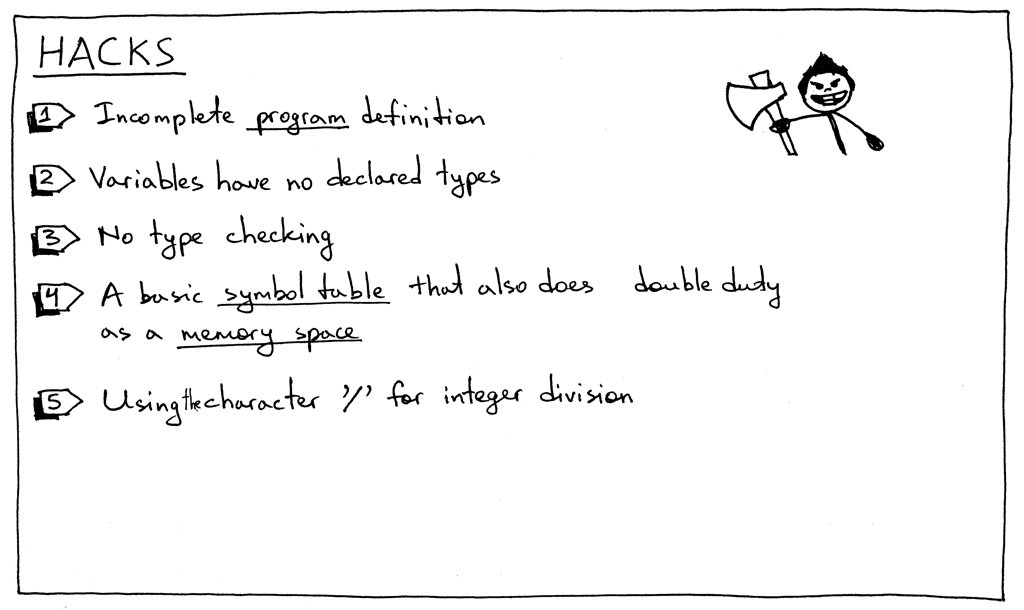
Figure 13: hacks
- 语法规则
program并不完整。我们会在后面扩展它。 - Pascal 是一门静态类型语言,你在使用一个变量之前必须声明它和它的类型。但是,你 也看到了,本文中并非如此。
- 暂时没有类型检查。现在这还不是一个大问题,我只是想明确地提出它。例如,一旦我 们往 interpreter 里添加了更多的类型,就需要在你尝试把两个字符串相加时报错。
- 本部分中的符号表是简单的 Python 字典还承担了内存空间的职责。不要担心:符号表 是如此重要以至于我会用几篇文章专门谈论它们。而且内存空间(运行时管理)也是单 独的主题。
- 在前面文章中我们简单的计算器中,我们用斜杠‘/’来表示整数除法。而在 Pascal 中你
必须使用关键字
div来表示整数除法(见练习1)。 - 还有一点是我故意引入的,这样你就可以在练习2中修正它:在 Pascal 中所有的关键字 和标识符都是不区分大小写的,但本文中的 interpreter 却是区分的。
下面是你的新练习,保持练习:
Figure 14: exercises
不像在许多其他语言中,Pascal 的变量和保留关键字并不区分大小写,因此
BEGIN,begin和BeGin都是同一个关键字。修改 interpreter 使得变量名和保留关键字 都不区分大小写。使用下面的程序来测试它:1
BEGIN BEGIN number := 2; a := NumBer; B := 10 * a + 10 * NUMBER / 4; c := a - - b end; x := 11; END.
- 我在前面“权宜之处”一节中提到过,我们的 interpreter 使用斜杠‘/’来表示整数除法,
而事实上,它应该使用 Pascal 的保留关键字
div来表示。修改 interpreter 使它 使用关键字div来表示整数除法,从而消除一个权宜之处。 - 修改 interpreter 使得变量也可以以下划线开头,就像‘num := 5’里一样。
这就是今天的所有内容。敬请关注,下次再见。
下面是我推荐的帮助你学习解释器和编译器的一些书:
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
顺便说一下,我还在写一本书“et’s Build A Web Server: First Steps”,解释了怎么从头 写一个基本的 Web 服务器。你可以从这里, 这里 和 这里 来感受一下这本书。
本系列的所有文章:
- Let’s Build A Simple Interpreter. Part 1.
- Let’s Build A Simple Interpreter. Part 2.
- Let’s Build A Simple Interpreter. Part 3.
- Let’s Build A Simple Interpreter. Part 4.
- Let’s Build A Simple Interpreter. Part 5.
- Let’s Build A Simple Interpreter. Part 6.
- Let’s Build A Simple Interpreter. Part 7.
- Let’s Build A Simple Interpreter. Part 8.
- Let’s Build A Simple Interpreter. Part 9.
- Let’s Build A Simple Interpreter. Part 10.
- Let’s Build A Simple Interpreter. Part 11.
- Let’s Build A Simple Interpreter. Part 12.
- Let’s Build A Simple Interpreter. Part 13.
- Let’s Build A Simple Interpreter. Part 14.