原文地址:Let’s Build A Simple Interpreter. Part 6.
今天是很重要的一天:)“为什么?”你可能会问。原因是今天我们会结束关于算术表达式的 讨论(好吧,基本结束),给我们的语法中加入括号,实现可以对嵌套任意层括号的表达式 进行求值,比如 7 + 3 * (10 / (12 / (3 + 1) - 1)).
让我们开始,好吗?
首先,要修改我们的语法使之支持括号。就像在第五部分中一样,规则 factor 被用来表
示表达式中的基本单元。在那篇文章中,我们仅有的基本单元就是整数。今天我们会增加另
一个基本单元──括号表达式。我们开始吧。
以下是更新后的语法:
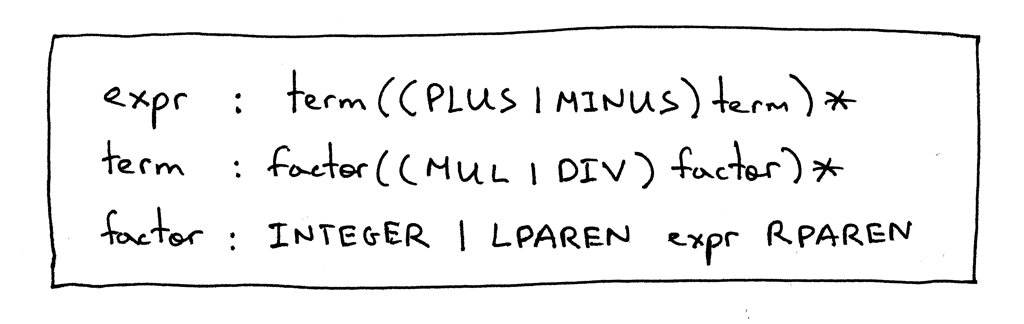
Figure 1: grammar
expr : term ((PLUS | MINUS) term)* term : factor ((MUL | DIV) factor)* factor : INTEGER | LPAREN expr RPAREN
产生式 expr 和 term 和第五部分中一样,只有产生式 factor 有一些变化,其中终
结符 LPAREN 表示左括号‘(’, RPAREN 表示右括号‘)’, 括号中间的非终结符 expr
引用了规则 expr.
以下是 factor 更新过的句法图,现在包含了多选一:
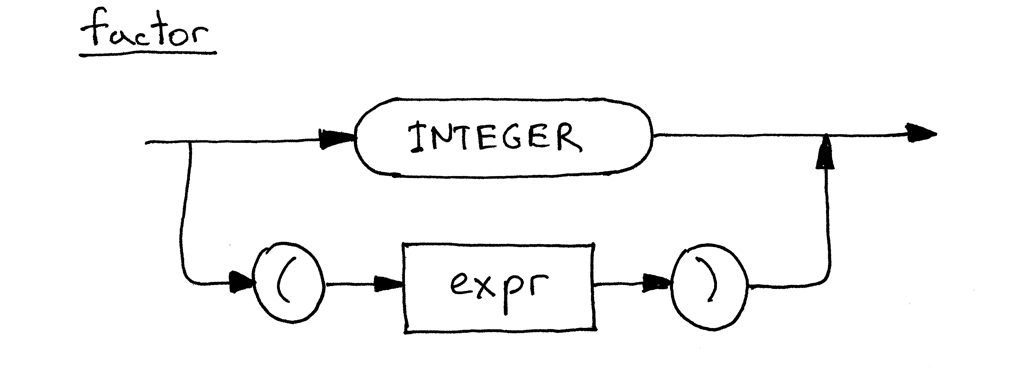
Figure 2: factor diagram
由于 expr 和 term 的语法规则没有改变,所以它们的语法图和第五部分中一样:
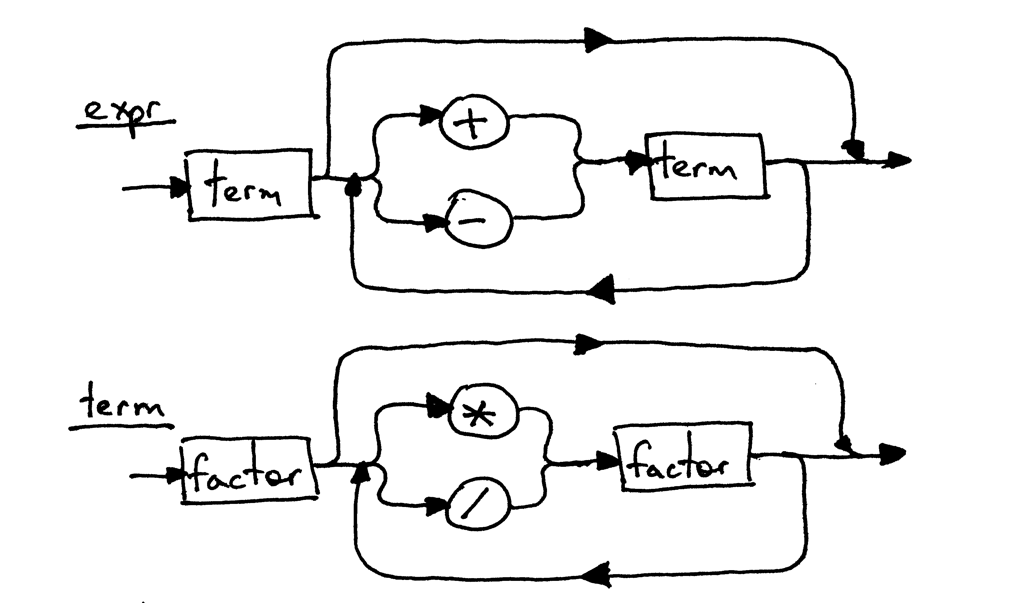
Figure 3: term diagram
我们的新语法中有一个有趣的特点──它是递归的。如果你尝试派生表达式 2 * (7 + 3), 会
由开始符号 expr 开始并在某一时刻递归地使用规则 expr 来派生原始算术表达式中的
(7 + 3) 部分。
让我们根据语法来分解表达式 2 * (7 + 3), 来看看它是如何工作的:
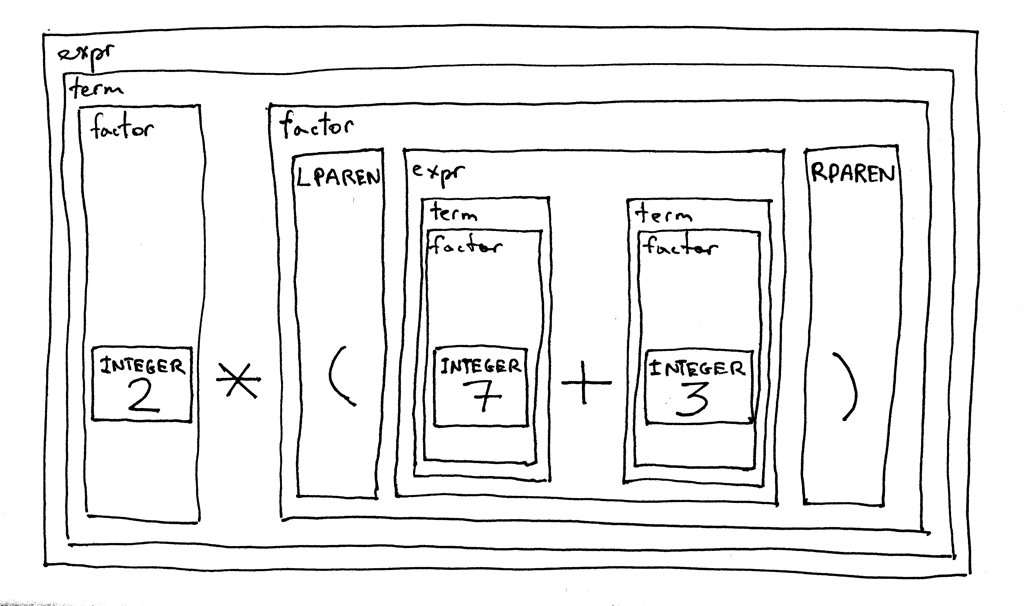
Figure 4: decomposition
一点提示:如果你需要复习一下递归,看一下Daniel P. Friedman 和 Matthias Felleisen 的《The Little Schemer》这本书──很不错。
好了,让我们继续前进把我们的新语法变成代码。
与前面的文章中的代码相比于最大的变化是:
Lexer修改后可以多返回两种 token: 表示左括号的 LPAREN 和表示右括号的 RPAREN.Interpreter的factor方法做了一点升级,现在除了整数还可以解析括号表达式。
下面是可以对包含整数、任意数量加减乘除操作符、嵌套任意层数的括号的算术表达式进行 求值的计算器的完整代码:
1 | # Token types |
将以上代码保存到名为 calc6.py 的文件中,自己尝试一下,确认你的新解释器可以正确
地对包含不同操作符和括号的算术表达式进行求值。
下面是某次运行过程:
$ python calc6.py calc> 3 3 calc> 2 + 7 * 4 30 calc> 7 - 8 / 4 5 calc> 14 + 2 * 3 - 6 / 2 17 calc> 7 + 3 * (10 / (12 / (3 + 1) - 1)) 22 calc> 7 + 3 * (10 / (12 / (3 + 1) - 1)) / (2 + 3) - 5 - 3 + (8) 10 calc> 7 + (((3 + 2))) 12
下面是今天的新练习:
Figure 5: exercises
- 如本文的描述,写一个你自己版本的算术表达式解释器。记住:重复是学习之母。
哈,你从头读到了尾!祝贺,你刚学到了(如果你做了练习──而且真的写了)怎么建立一个 基本的可以处理相当复杂算术表达式的 递归下降parser/interpreter.
下一篇文章我会讨论 递归下降parser 的更多细节。我还会介绍一个构建解释器和编译器 时非常重要的且广泛应用的数据结构,这个系列中都会用到。
敬请关注,很快再见。直到下次之前,继续学习解释器而且别忘了最重要的事:玩得开心, 享受这个过程!
下面是我推荐的帮助你学习解释器和编译器的一些书:
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
- Modern Compiler Implementation in Java
- Modern Compiler Design
- Compilers: Principles, Techniques, and Tools (2nd Edition)
顺便说一下,我还在写一本书“et’s Build A Web Server: First Steps”,解释了怎么从头 写一个基本的 Web 服务器。你可以从这里, 这里 和 这里 来感受一下这本书。
本系列的所有文章:
- Let’s Build A Simple Interpreter. Part 1.
- Let’s Build A Simple Interpreter. Part 2.
- Let’s Build A Simple Interpreter. Part 3.
- Let’s Build A Simple Interpreter. Part 4.
- Let’s Build A Simple Interpreter. Part 5.
- Let’s Build A Simple Interpreter. Part 6.
- Let’s Build A Simple Interpreter. Part 7.
- Let’s Build A Simple Interpreter. Part 8.
- Let’s Build A Simple Interpreter. Part 9.
- Let’s Build A Simple Interpreter. Part 10.
- Let’s Build A Simple Interpreter. Part 11.
- Let’s Build A Simple Interpreter. Part 12.
- Let’s Build A Simple Interpreter. Part 13.
- Let’s Build A Simple Interpreter. Part 14.