原文地址:Let’s Build A Simple Interpreter. Part 1.
If you don't know how compilers work, then you don't know how computers work. If you're not 100% sure whether you know how compilers work, then you don't know how they work. – Steve Yegge
就是这样。仔细想想这事儿。不管你是新手还是有经验的软件开发者:如果你不知道编译器 或者解释器怎么工作,那么你就不知道计算机怎么工作。就这么简单。
那么,你知道编译器和解释器怎么工作吗?而且,你 100% 确定你知道他们怎么工作的?如 果你不知道。
或者你不知道又对此很纠结。
OMG! What am I supposed to do ?
别担心。如果你不中断,看完整个系列,并且跟我一起建一个解释器和一个编译器,最后你 就会知道它们是如何工作的。而且你会变成一个自信快乐的 camper。至少我希望如此。
为什么要你学解释器和编译器?我将给你三条理由。
- 要写一个解释器或编译器,你必须同时用到很多技术。编写一个解释器或编译器会帮助 你提高这些技能并且成为一个更好的软件开发者。而且,你将学到的这些技能在开发任 何软件时都有可能用到,而不仅仅是解释器或编译器。
- 你确实想要知道计算机如何工作。一般解释器和编译器看上去都像魔法一样。但你不应 该对这些魔法感到舒服。你想要揭开解释器和编译器的神秘面纱,理解它们如何工作并 控制所有一切。
- 你想要创造自己的编程语言或者领域特定语言。如果是这样,你就需要为这个语言创建 一个解释器或编译器。最近,创建新语言再度兴起。你几乎每天都可以看到一门新语言 的诞生:Elixir, Go, Rust 等。
好了,但什么是解释器和编译器呢?
解释器 或 编译器 的目标都是将某种高级语言的源代码翻译成另一种形式。不清楚, 是吧?忍耐一下,在这个系列的后续中你将会学习到源代码到底翻译成了什么。
现在你可能还会对解释器和编译器之间的区别感到疑惑。为了这个系统的目的,我们约定如 果一个翻译器把源代码翻译成了机器码,那它就是 编译器 。如果一个翻译器在处理和执 行源代码之前没有把它翻译成机器码,它就是 解释器 。它们看起来像下面这样:
我希望到现在为止你已经被说服且真的想要学习并构建一个解释器和编译器。在解释器方面 你可以对这个系列有什么期待呢?
是这样的。你将和我一起为 Pascal 语言的一个子集创建一个简单的解释器。在这个系列结 束时你将会有一个可以工作的 Pascal 解释器和一个类似 Python pdb 的源码级别的调试器。
你可能会问,为什么是 Pascal?一方面,它不是我为这个系列编造出来的语言:它是一个 拥有许多重要语文结构的真实编程语言。而且一些较老(但仍有用)的 CS 书籍在它们的例 子中使用 Pascal(我知道用这个理由选择要为之编写解释器的语言并不很吸引人,但我觉 得这是一个学习一门非主流语言的好机会:)
这是一个用 Pascal 写的阶乘函数的例子,你将可以使用你自己的解释器来解释它,并且用 在这个过程中创建的交互式源码级调试器来调试它:
1 | program factorial; function factorial(n: integer): longint; begin if n = 0 then factorial := 1 else factorial := n * factorial(n - 1); end; var n: integer; begin for n := 0 to 16 do writeln(n, '! = ', factorial(n)); end. |
用来实现 Pascal 解释器的语言是 Python,但你可以用任何你想用的语言,因为这时介绍 的方法并不依赖任何实现语言。好了,让我们开始正事吧。就位,预备,出发!
你编写解释器和编译器的第一次尝试将会是写一个算术表达式的简单解释器,也就是一个计 算器。今天的目标很简单:让你的计算器处理两个一位整数相加,如 3+5。下面是你计算器, 啊不,解释器的源码:
1 | # Token types |
把以上代码保存到名为 calc1.py 中,或者直接从 GitHub 上下载。在你开始仔细研究代
码之前,在命令行上运行这个计算器并看它实现运行。把玩一下!下面是在我笔记本上的一
次尝试(如果你想在 Python3 下运行,就需要把 raw_input 替换为 =input=):
$ python calc1.py calc> 3+4 7 calc> 3+5 8 calc> 3+9 12 calc>
要想让你的小计算器不抛异常正常工作,你的输入需要遵循以下规则:
- 只输入一位的数字
- 现阶段仅支持加法操作
- 输入中不允许有空白符
这些约束使得构建一个计算器很简单。别担心,你很快就会使它变得很复杂了。
好了,现在让我们钻进去看看你的解释器是怎么工作的,怎么对算术表达式求值的。
当你在命令行上输入一个表达式 3+5 时,你的解释器得到一个字符串 “3+5”。为了使解释
器真正理解如何处理这个字符串,需要先把输入的 “3+5” 拆分成被叫做 token 的部件。
token 就是一个有类型的值的对象。例如对于字符串“3”来说,token 类型为 INTEGER ,
相应的值是整数 3 。
把输入字符串拆分成 token 的过程被称为 词法分析 (lexical analysis)。所以,解释 器要做的第一步就是读取输入的字符串并把他转化成 token 流。解释器中做这个工作的部 分被称为 词法分析器 (lexical analyzer),简称 lexer 。你也可能会遇到这个部分 被叫做其他名字,如 scanner 或 tokenizer 。他们的含义是一样的:表示解释器或编 译器中将输入的字符串转化为 token 流的部分。
解释器中的 get_next_token 方法就是你的词法分析器。你每次调用它,就会从输入到解
释器的字符流中得到下一个 token。让我们仔细看一下这个方法,看看它是怎么把字符转化
为 token 的。输入被存放在变量 text 中,它保存了输入的字符串, pos 是指向该字
符串的一个索引(把字符串看作是一个字符数组)。 pos 的初值被设为 0, 指向字符‘3’。
该方法首先检查该字符是不是数字,如果是就递增 pos 并返回一个类型为 INTEGER 值
为整数 3 的 token。:
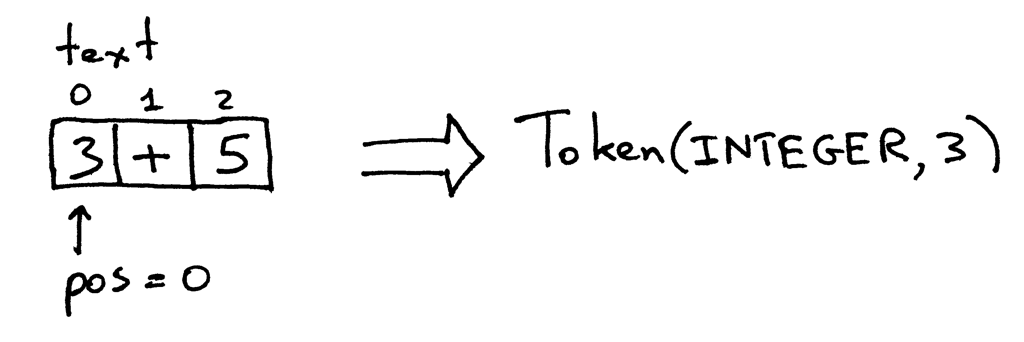
Figure 1: lexer1
现在 pos 指向了 text 中的字符‘+’。下次你调用这个方法时,它会先测试 pos 位
置的字符是否是数字,然后测试它是否是加号,此时它是加号。这样该方法就递增 pos
并返回一个类型为 PLUS 值为‘+’的 token:
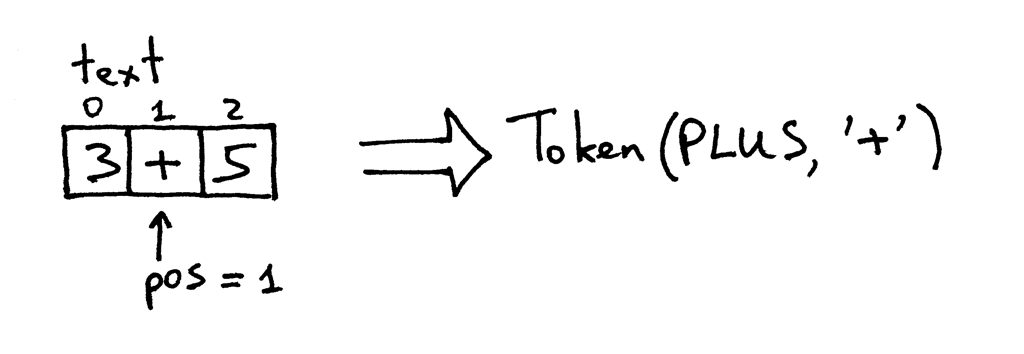
Figure 2: lexer2
现在 pos 指向了字符‘5’。当你再次调用 get_next_token 时,它会检查 pos 位置
是否是一个数字,此时是的,因此它递增 pos 并返回一个类型为 INTEGER 值为‘5’的
token:
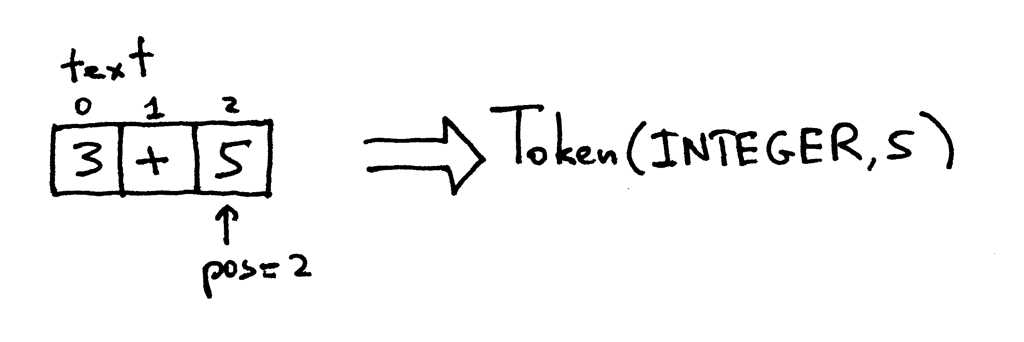
Figure 3: lexer3
现在索引 pos 越过了字符串“3+5”的末尾,接下来每次调用 get_next_token 方法都会
返回 EOF token:
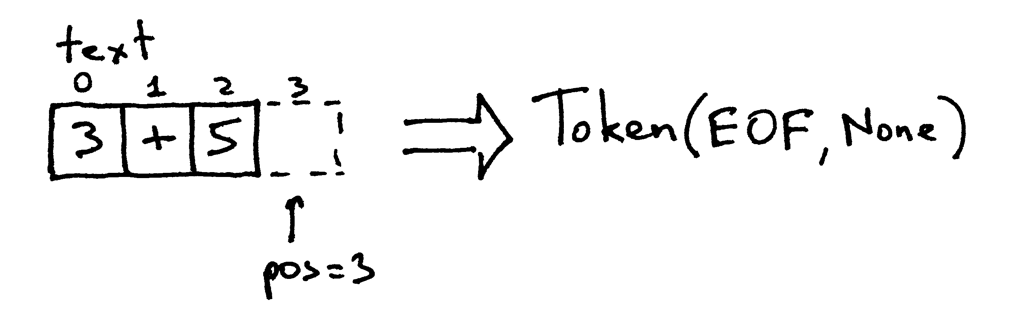
Figure 4: lexer4
自己动手试试看看你的计算器的 lexer 组件怎么工作的:
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
此时你的解释器已经可以从输入的字符流中获得 token 流了,解释器需要对它做点什么:
它需要从使用 lexer get_next_token 得到的扁平字符流中找到结构。你的解释器期望从
流中找到如下的结构: INTEGER -> PLUS -> INTEGER. 即,它试着找到这样一个 token 序
列:整数后跟一个加号再跟一个整数。
负责查找和解释这个结构的方法是 expr. 这个方法验证一个 token 序列是否遵从期望的
token 序列,即 INTEGER -> PLUS -> INTEGER. 当确定遵从这个结构后,它就把 PLUS 左
边和右边 token 的值相加来生成结果,从而成功地解释了你传给解释器的算术表达式。
expr 方法使用了辅助方法 eat 来验证传给 eat 的 token 类型与当前的 token 类
型相匹配。在匹配到传入的 token 类型后, eat 方法会取得下一个 token 并把它赋值
给变量 current_token, 这样实际上是“吃掉”了当前匹配的 token 并把想象中的 token
流中的指针向前移动了。如果 token 流中的结构不遵从期望的 INTEGER PLUS INTEGER 序
列, eat 方法就会抛出一个异常。
让我们回顾一下你的解释器为了对一个算术表达式求值都做了什么:
- 解释器接收一个输入字符串,设为“3+5”
- 解释器调用了
expr方法来从词法解析器get_next_token返回的 token 流中寻找 一个结构。这个结构就是一个 INTEGER PLUS INTEGER 的形式。当确认了这个结构以后, 它就使用把两个 INTEGER token 相加的方式来解释这个输入,因为此时解释器已经清楚 地知道它要做的就是把 3 和 5 两个整数相加。
祝贺你。你刚刚学会了怎么构造你的第一个解释器!
现在是时候做此练习了。

Figure 5: exercises2
你不会觉得你刚刚读了这篇文章就足够了,是吧?好了,自己动手做下面的练习:
- 修改代码使得允许输入多位整数,例如“12+3”
- 增加一个跳过空白符的方法,使你的计算器可以处理包含空白符的输入如 “ 12 + 3”
- 修改代码使得它可以处理‘-’而非‘+’的情况
检查你的理解。
- 什么是解释器?
- 什么是编译器?
- 解释器和编译器的区别是什么?
- 什么是 token?
- 将输入拆分成 token 的过程叫什么?
- 解释器中做词法分析的部分叫什么?
- 解释器或编译器的这个部分还有什么其他常见的名字?
在结束本文之前,我真的很希望你坚持学习解释器和编译器。并且我想让你现在就开始。不 要推到以后。不要等待。如果你刚浏览了本文,请重来一遍。如果你认真地读了一遍但还没 做练习──现在就做。如果你只做了一部分,就完成剩下的。你已经知道我的意思了。你以为 这就完了?签下这张保证今天就开始学习解释器和编译器的保证书!
我,__________,在意识和身体都清醒的情况下,在此承诺从今天开始坚持学习解释器和编 译器直到我 100% 知道它们怎么工作为止!
签名: 日期:

Figure 6: commitment pledge
署名,填写日期,把它放在一个你每天都能看到的地方来确保你信守了承诺。并铭记承诺的 含义:
Commitment is doing the thing you said you were going to do long after the mood you said it in has left you.
— Darren Hardy
好了,今天到这儿。这个小系列下一篇文章将会扩展你的计算器,使它处理更多算术表达式。 敬请关注。
如果你等不及第二篇文章,大嚼代码准备深入钻研解释器和编译器,我推荐下面一些书来帮 助你完成这个旅程:
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
- Modern Compiler Implementation in Java
- Modern Compiler Design
- Compilers: Principles, Techniques, and Tools (2nd Edition)
顺便说一下,我还在写一本书“et’s Build A Web Server: First Steps”,解释了怎么从头 写一个基本的 Web 服务器。你可以从这里, 这里 和 这里 来感受一下这本书。
本系列的所有文章:
- Let’s Build A Simple Interpreter. Part 1.
- Let’s Build A Simple Interpreter. Part 2.
- Let’s Build A Simple Interpreter. Part 3.
- Let’s Build A Simple Interpreter. Part 4.
- Let’s Build A Simple Interpreter. Part 5.
- Let’s Build A Simple Interpreter. Part 6.
- Let’s Build A Simple Interpreter. Part 7.
- Let’s Build A Simple Interpreter. Part 8.
- Let’s Build A Simple Interpreter. Part 9.
- Let’s Build A Simple Interpreter. Part 10.
- Let’s Build A Simple Interpreter. Part 11.
- Let’s Build A Simple Interpreter. Part 12.
- Let’s Build A Simple Interpreter. Part 13.
- Let’s Build A Simple Interpreter. Part 14.